CORE participated at the Open Repositories conference (10 – 13 June 2019), which took place in Hamburg, Germany. This year’s conference theme was “All the user needs”, where CORE received much attention and participated actively with 5 presentations.
Assessing Compliance with the UK REF 2021 Open Access Policy
The recent increase in Open Access (OA) policies has brought forth important questions concerning the effect these policies have on the practice of publishing Open Access. In particular, is there evidence to support that mandating OA increases the proportion of OA outputs (in other words, do authors comply with relevant policies)? Furthermore, does mandating OA reduce the time from acceptance to the public availability of research outputs, and can compliance with OA mandates be effectively tracked? This work studies compliance with the UK REF 2021 Open Access policy. We use data from CrossRef and from CORE to create a dataset containing 1.6 million publications. We show that after the introduction of the UK OA policy, the proportion of OA research outputs in the UK has increased significantly, and the time lag between the acceptance of a publication and its Open Access availability has decreased, although there are significant differences in compliance between different repositories. We have developed a tool that can be used to assess publications’ compliance with the policy based on a list of DOIs.read more...
=&0=&This post was authored by Nancy Pontika, Lucas Anastasiou and Petr Knoth.
The CORE team is thrilled to announce the release of a new version of our recommender; a plugin that can be installed in repositories and journal systems to suggest similar articles. This is a great opportunity to improve the functionality of repositories by unleashing the power of recommendation over a huge collection of open-access documents, currently 37 million metadata records and more than 4 million full-text, available in CORE.
Recommender systems and the CORE Plug-In
Typically, a recommender tracks a user’s preferences when browsing a website and then filters the user’s choices suggesting similar or related items. For example, if I am looking for computer components at Amazon, then the service might send me emails suggesting various computer components. Amazon is one of the pioneers of recommenders in the industry being one of the first adopters of item-item collaborative filtering (a method firstly introduced in 2001 by Sarwar et al. in a highly influential scientific paper of modern computer science).
Over the years, many recommendation methods and their variations have been suggested, evaluated both by academia and industry. From a user’s perspective, recommenders are either personalised, recommendations targeted to a particular user, based on the knowledge of the user’s preferences or past activity, or non-personalised, recommending the same items to every user.
From a technological perspective, there are two important classes of recommender systems: collaborative filtering and content based filtering.
1. Collaborative filtering (CF):
Techniques in this category try to match a user’s expected behaviour over an item according to what other users have done in the past. It starts by analysing a large amount of user interactions, ratings, visits and other sources of behaviour and then builds a model according to these. It then predicts a user’s behaviour according to what other similar users – neighbour users – have done in the past – user-based collaborative filtering.
The basic assumption of CF is that a user might like an unseen item, if it is liked by other users similar to him/her. In a production system, the recommender output can then be described as, for example, ‘people similar to you also liked these items.’
These techniques are now widely used and have proven extremely effective exploratory browsing and hence boost sales. However, in order to work effectively, they need to build a sufficiently fine-grained model providing specific recommendations and, thus, they require a large amount of user-generated data. One of the consequences of insufficient amount of data is that CF cannot recommend items that no user has acted upon yet, the so called cold-items. Therefore, the strategy of many recommender systems is to expose these items to users in some way, for example either by blending them discretely to a home page, or by applying content-based filtering on them decreasing in such way the number of cold-items in the database.
While CF can achieve state-of-the-art quality recommendations, it requires some sort of a user profile to produce recommendations. It is therefore more challenging to apply it on websites that do not require a user sign-on, such as CORE.
2. Content-based filtering (CBF)
CBF attempts to find related items based on attributes (features) of each item. These attributes could be, for example the item’s name, description, dimensions, price, location, and so on.
For example, if you are looking in an online store for a TV, the store can recommend other TVs that are close to the price, screen size, and could also be similar – or the same – brand, that you are looking for, be high-definition, etc. The advantage of content-based recommendations is that they do not suffer from the cold-start problem described above. The advantage of content-based filtering is that it can be easily used for both personalised and non-personalised recommendations.
The CORE recommendation system
There is a plethora of recommenders out there serving a broad range of purposes. At CORE, a service that provides access to millions of research articles, we need to support users in finding articles relevant to what they read. As a result, we have developed the CORE Recommender. This recommender is deployed within the CORE system to suggest relevant documents to the ones currently visited.
In addition, we also have a recommender plugin that can be installed and integrated into a repository system, for example, EPrints. When a repository user views an article page within the repository, the plugin sends to CORE information about the visited item. This can include the item’s identifier and, when possible, its metadata. CORE then replies back to the repository system and embeds a list of suggested articles for reading. These actions are generated by the CORE recommendation algorithm.
How does the CORE recommender algorithm work?
Based on the fact that the CORE corpus is a large database of documents that mainly have text, we apply content-based filtering to produce the list of suggested items. In order to discover semantic relatedness between the articles in our collection, we represent this content in a vector space representation, i.e. we transform the content to a set of term vectors and we find similar documents by finding similar vectors.
The CORE Recommender is deployed in various locations, such as on the CORE Portal and in various institutional repositories and journals. From these places, the recommender algorithm receives information as input, such as the identifier, title, authors, abstract, year, source url, etc. In addition, we try to enrich these attributes with additional available data, such as citation counts, number of downloads, whether the full-text available is available in CORE, and more related information. All these form the set of features that are used to find the closest document in the CORE corpus.
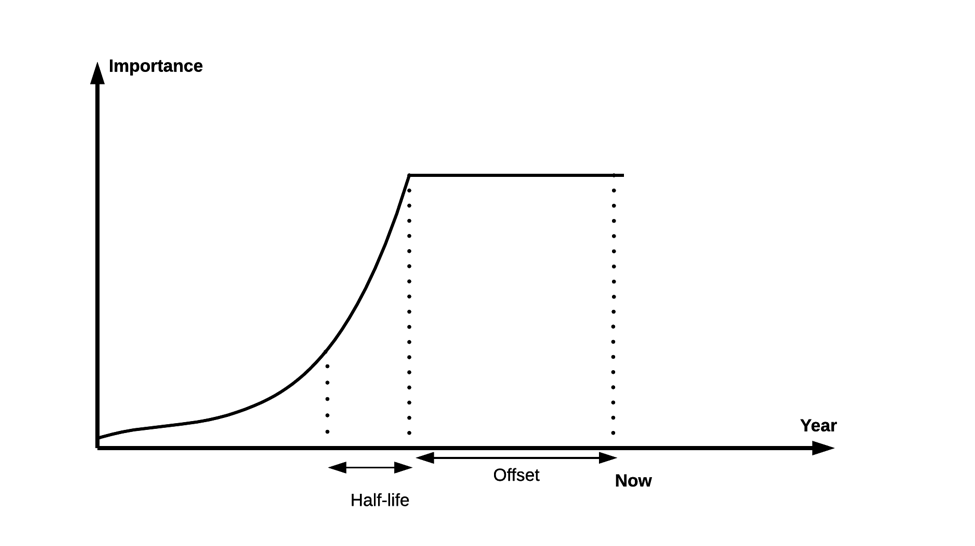
Of course not every attribute has the same importance as others. In our internal ranking algorithm we boost positively or negatively some attributes, which means that we weigh more or less some fields to achieve better recommendations. In the case of the year attribute, we go even further, and apply a decay function over it, i.e. recent articles or articles published a couple of years ago get the same boosting (offset), while we reduce the importance of older articles by 50% every N years (half-life). In this way recent articles retain their importance, while older articles contribute less to the recommendation results.
Decay function in year attribute
Someone may ask:
how do you know which weight to put in each field you are using? How did you come up with the parameters used in the decay function?read more...