We are glad to announce that CORE has reached a new milestone of 30 million monthly users. This follows already significant growth of CORE’s user base in 2020, as we only reported achieving 20 million monthly users in June 2020.
The first quarter of 2020 was a highly productive period for CORE in terms of growing and developing our products. Details about these and more news can be found below.
CORE is ready to release a premium version of the Repository Dashboard
The CORE team has developed a premium edition of the CORE Repository Dashboard, with a particular focus being on the development of features that support compliance assessment with the REF 2021 Open Access Audit.
The new CORE Repository Dashboard contains a brand new REF compliance and DOI enrichment tabs. This service has been developed to support Higher Educational Institutions (HEIs) with repositories. More specifically, repository managers, research administrators, etc. The interface offers valuable technical information and statistics. Users can benefit from the tool by accessing information that will help them to improve the harvesting of their repository outputs and increase the visibility of their content. The premium edition is currently available to a limited number of users and we plan to expand to all interested institutions in the future. The release of the new version will be announced through a CORE blog-post.read more...
CORE releases CORE Discovery in Mozilla and Opera browsers
CORE Discovery, a browser extension that offers one-click access to free copies of research papers whenever you might hit a paywall, is now published in Mozilla and Opera Stores. The plug in was originally released as a Google Chrome extension.
CORE presents its full texts growth and introduces eduTDM at Open Science Fair 2019
CORE was active at the Open Science Fair 2019, an international event for all topics related to Open Science. CORE had two posters at this event; a general to the CORE service poster, which updated the community about the full text growth and wide usage of the CORE services, and a second one about the eduTDM.read more...
This was another productive year for the CORE team; our content providers have increased, along with our metadata and full text records. This makes CORE the world’s largest open access aggregator
. More specifically, over the last 3 months CORE had more than 25 million users, tripling our usage compared to 2017. According to read more...
For yet another year (see previous years 2016, 2015) CORE has been really productive; the number of our content providers has increased and we have now more open access full text and metadata records than ever.
Our services are also growing steadily and we would like to thank the community for using the CORE API and CORE Datasets.
by George Macgregor, Institutional Repository Coordinator, University of Strathclyde
This guest blog post briefly reviews why the CORE Recommender was quickly adopted on Strathprints and how it has become a central part of our quest to improve the interactive qualities of repositories.
Back in October 2016 my colleagues at the CORE Team released their Recommender plugin. The CORE Recommender plugin can be installed on repositories and journal systems to recommend similar scholarly content. On this very blog, Nancy Pontika, Lucas Anastasiou and Petr Knoth, announced the release of the Recommender as a:
…great opportunity to improve the functionality of repositories by unleashing the power of recommendation over a huge collection of open-access documents, currently 37 million metadata records and more than 4 million full-text, available in CORE*.
(* Note from CORE Team: the up-to-date numbers are 80,097,014 metadata and 8,586,179 full-text records.).
When the CORE Recommender is deployed a repository user will find that as they are viewing an article or abstract page within the repository, they will be presented with recommendations for other related research outputs, all mined from CORE. The Recommender sends data about the item the user is visiting to CORE. Such data include any identifiers and, where possible, accompanying metadata. The CORE response to the repository then delivers CORE’s content recommendations and a list of suggested related outputs are presented to the user in the repository user interface. The algorithm used to compute these recommendations is described in the original CORE Recommender blog post but is ultimately based on content-based filtering, citation graph analysis and analysis of the semantic relatedness between the articles in the CORE aggregation. It is therefore unlike most standard recommender engines and is an innovative application of open science in repositories.
Needless to say, we were among the first institutions to proudly implement the CORE Recommender on our EPrints repository. The implementation was on Strathprints, the University of Strathclyde’s institutional repository, and was rolled out as part of some wider work to improve repository visibility and web impact. The detail of this other work can be found in a poster presented at the 2017 Repository Fringe Conference and
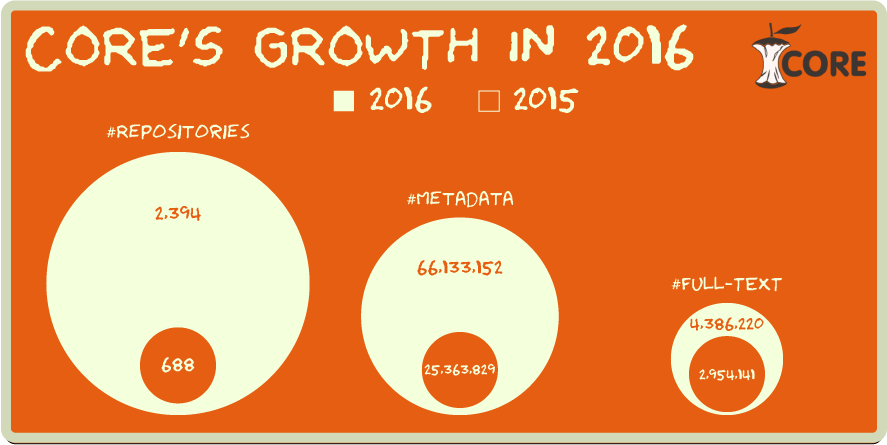
CORE is continuously growing. This month we have reached 75 million metadata and 6 million full of text scientific research articles harvested from both open access journals and repositories. This past February we reported 66 million metadata and 5 million full text articles, while at the end of December 2016 we had just over 4 million full text. This shows our continuous commitment to bring to our users the widest possible range of Open Access articles.
To celebrate this milestone, we gathered the knowledge of our data scientists, programmers, researchers, and designers to illustrate our portion of metadata and full text with a less traditional (sour apple) “pie chart”. read more...
CORE is thrilled to announce that it currently provides 5 millions of open access full-text papers.
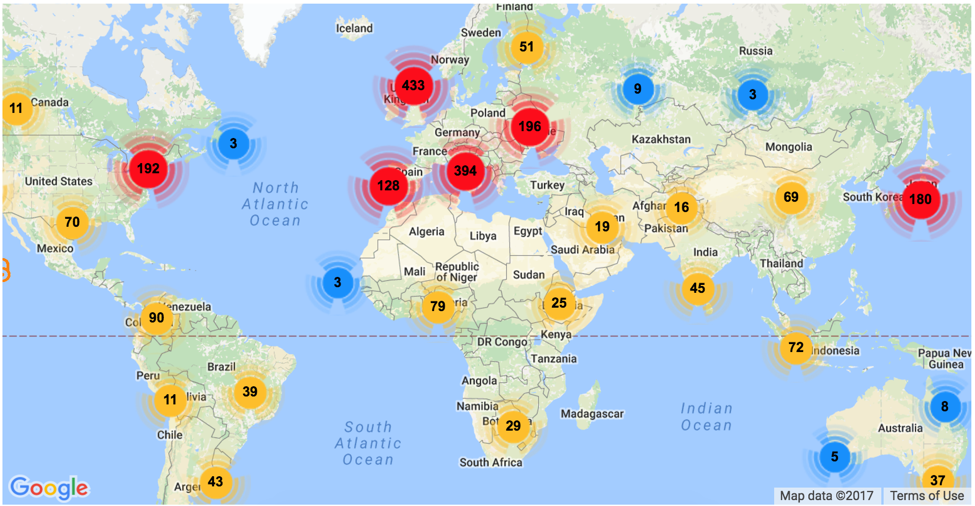
CORE’s data providers from around the world
“In the last year, we have managed to scale up our harvesting process. This enabled us to significantly increase the amount of open access content we can offer to our users. With more and more open access content being made available by data providers, thanks to recent open access policies, CORE now also captures and provides access to a higher percentage of global research literature ”, says CORE’s founder, Dr Petr Knoth.
With 66 million metadata records and 5 million full-text, from 102 countries, in 52 different languages, CORE becomes now the world’s largest full-text open access aggregator. CORE embraces the vibrant collections of both institutional and disciplinary repositories, while its large volume of scholarly outputs ranges from scientific research papers, to grey literature and from Master’s to Doctoral thesis. In addition, it is a metasearch for the all the open access peer-reviewed scientific journal articles published in open access journals. read more...
The past year has been productive for the CORE team; the number of harvested repositories and our open access content, both in metadata and full-text, has massively increased. (You can see last year’s blog post with our 2015 achievements in numbers here.)
There was also progress with regards to our services; the number of our API users was almost doubled in 2016, we have now about 200 registered CORE Dashboard users, and this past October we released a new version of our recommender and updated our dataset.
Around this time of the year, the joyful Christmas spirit of the CORE team increases along with our numbers. Thus, we decided to recalculate how far are the CORE research outputs – if we had printed them – from reaching the moon (last year we made it to 1/3 of the way).
We are thrilled to see that this year we got CORE even closer to the moon! We would also like to thank all our data providers, who have helped us reaching this goal.
Fear not, we will never print all our research outputs, we believe that their mission is to be discoverable on the web as open access. Plus we love trees.
Merry Christmas from the CORE Team!
* Note: Special thanks to Matteo Cancellieri for creating the CORE graphics.