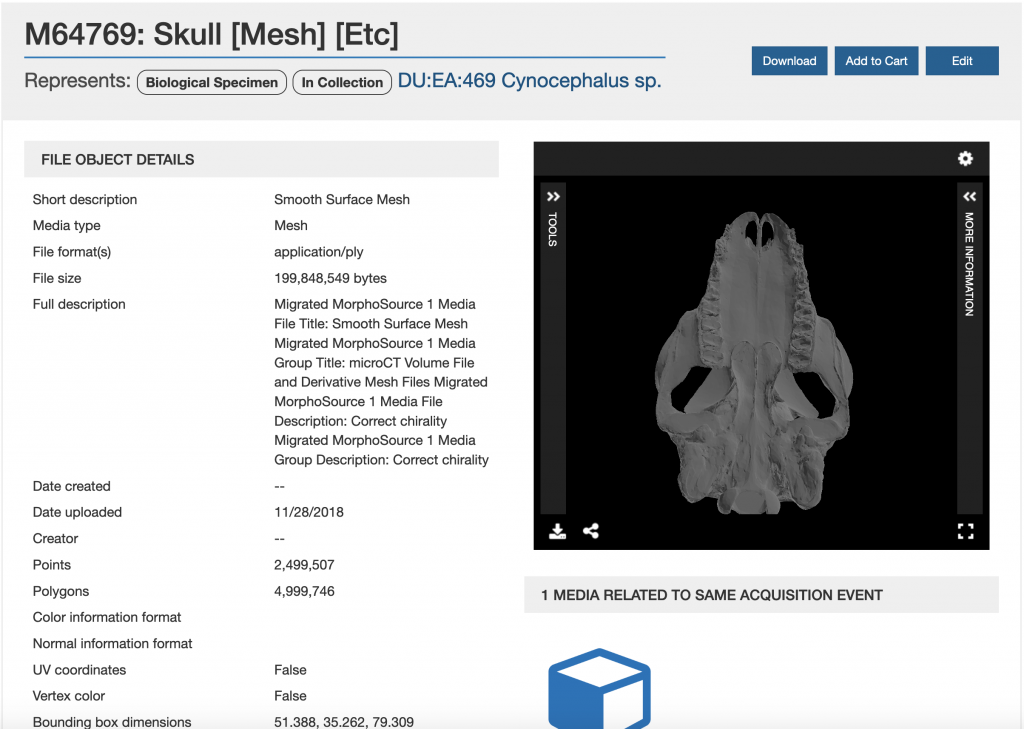
It’s an exciting time for the MorphoSource team, as we work to launch the MorphoSource 2 Beta application next Wednesday!
The new application improves and expands upon the original MorphoSource, a repository for 3D research data, and is being built using Hyrax, an open-source digital repository application widely implemented by libraries to manage digital repositories and collections. The team has been working on the site for the last two and a half years, and is looking forward to our efforts being made available to the MorphoSource community. At launch, users will be able to access records for over 140,000 media files, contributed by 1,500 researchers from all over the world.
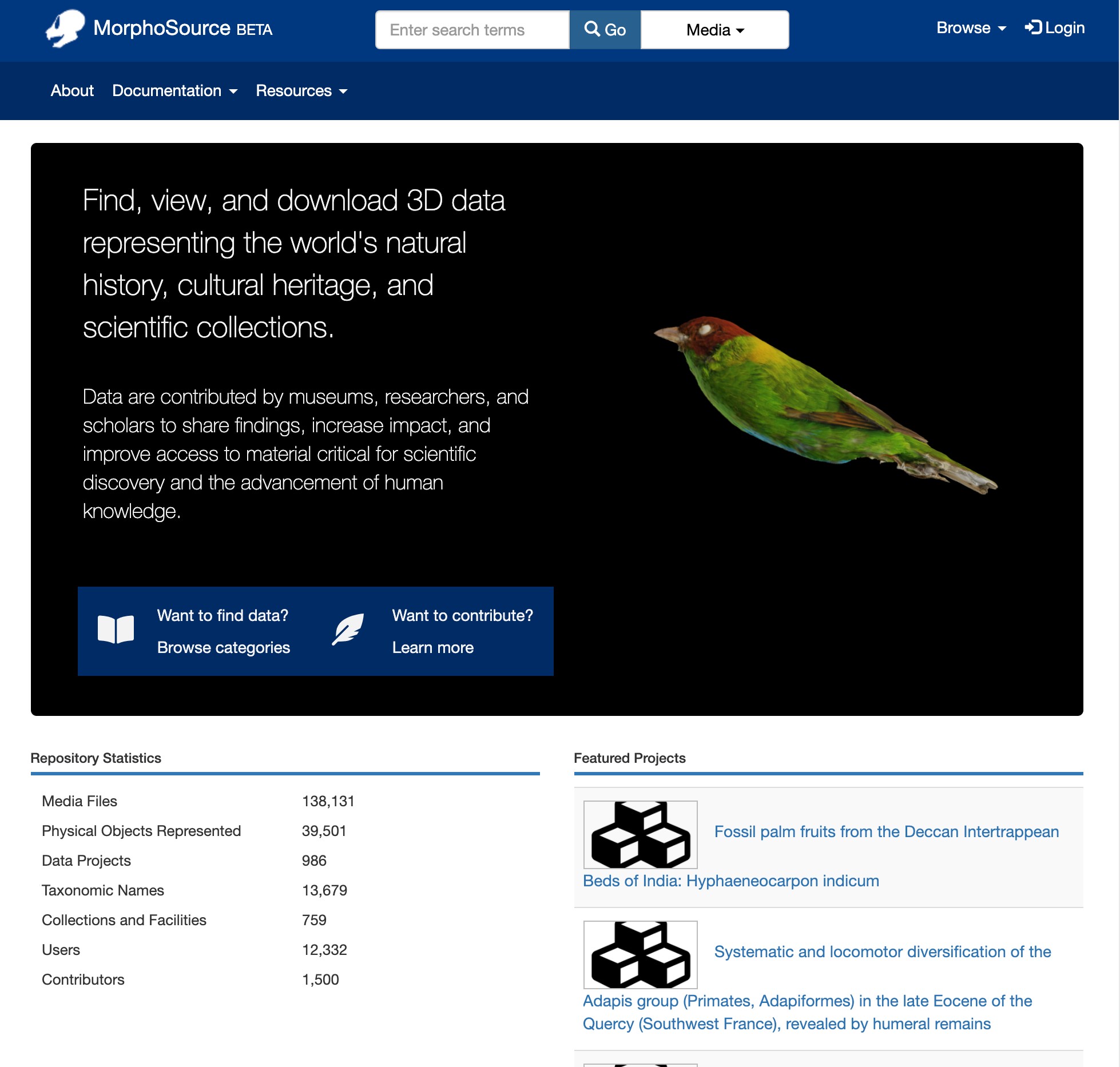
While the current site is still available for browsing at www.morphosource.org, we are migrating the repository data over to the new site in preparation for the launch, and have paused the ingest of new data sets. When the migration is complete, users will be able to access the new application at the current url. Users with an account on the old site will be able to log in to the new site using their MorphoSource 1 credentials.
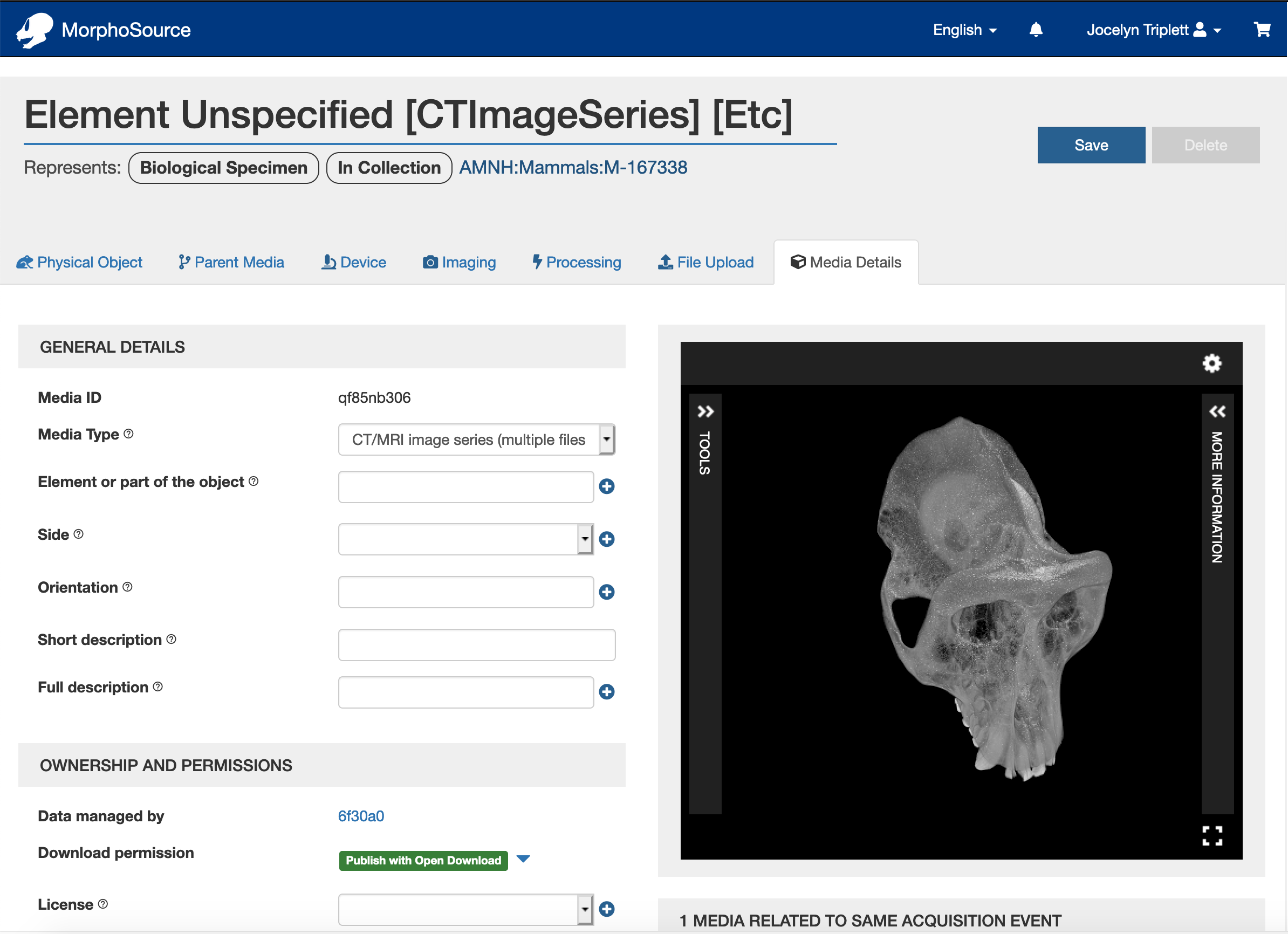
In my last post in June, I described some of the features that were in development at that time. In this post, I’ll highlight a few recent additions with screenshots from the beta site: Browse, Search, and User Dashboards.
Browse
Browse pages have been added as a quick entry point for users to discover data in several different ways. Users can use these pages to immediately access media, biological specimens, cultural heritage objects, organizations, teams, or projects.

Media Types and Modalities: Users can view all media records of a specific file type, such as image, CT image series, or mesh or point cloud. There are also links to records created by different methods, such as X-Ray, Magnetic Resource Imaging, or Photogrammetry.
Physical Object Types: Links to view either all the Biological Specimens or Cultural Heritage Objects in MorphoSource
Biological Taxonomy: Users can find specimen records through the taxonomy browse by drilling down through the taxonomic ranks. The MorphoSource taxonomy records have been imported from the GBIF Backbone Taxonomy or have been created by MorphoSource users.
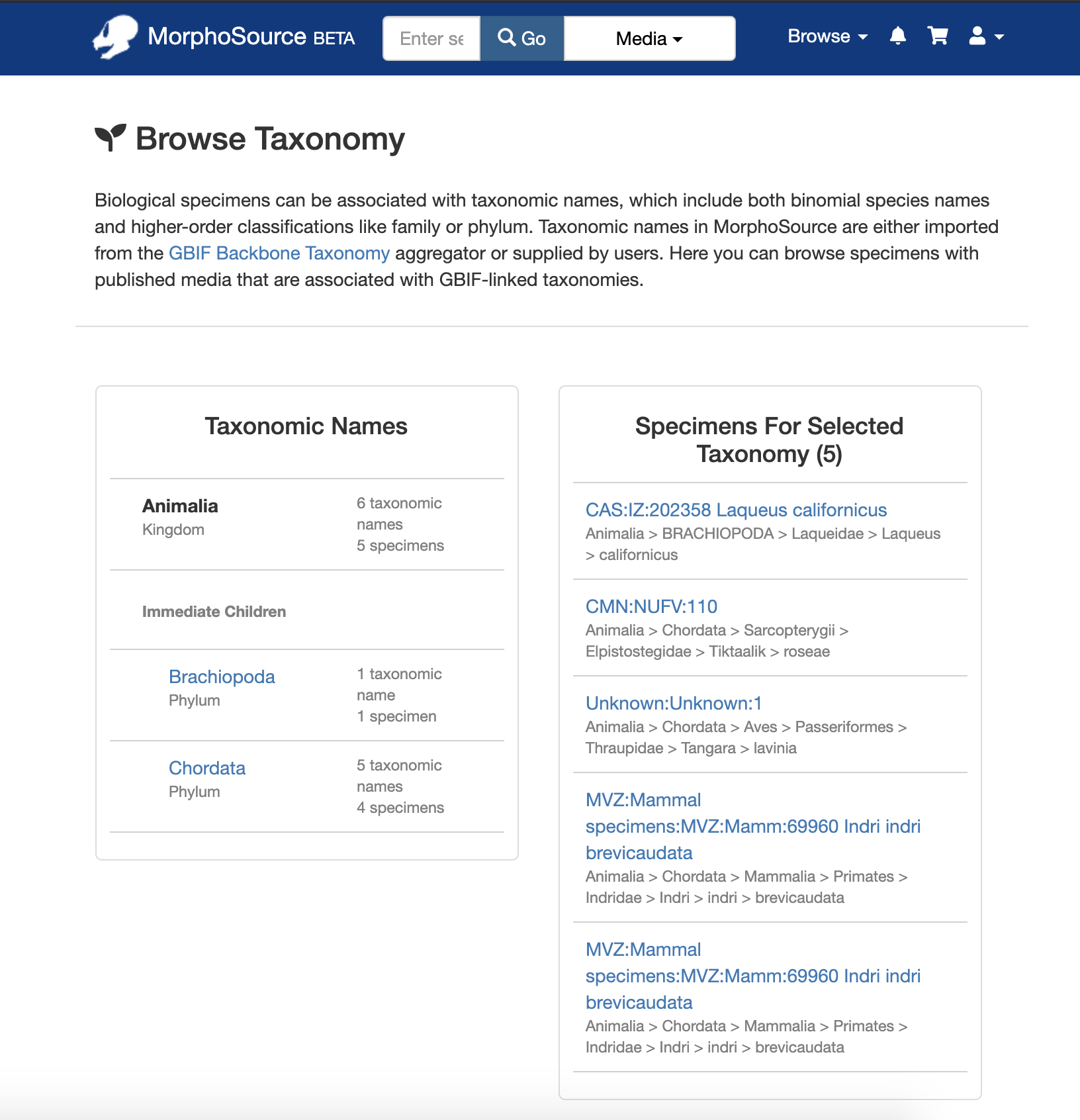
Projects: Projects are user-created groupings of media and specimens. From the browse page, projects can be searched by title and sorted by title, description, team, creator, or number of associated media or objects.

Teams: Teams are groups of MorphoSource users that share management of media and team projects. A Team may be associated with an organization. The Team browse page lets users search and sort teams in a similar way to the Projects browse page.
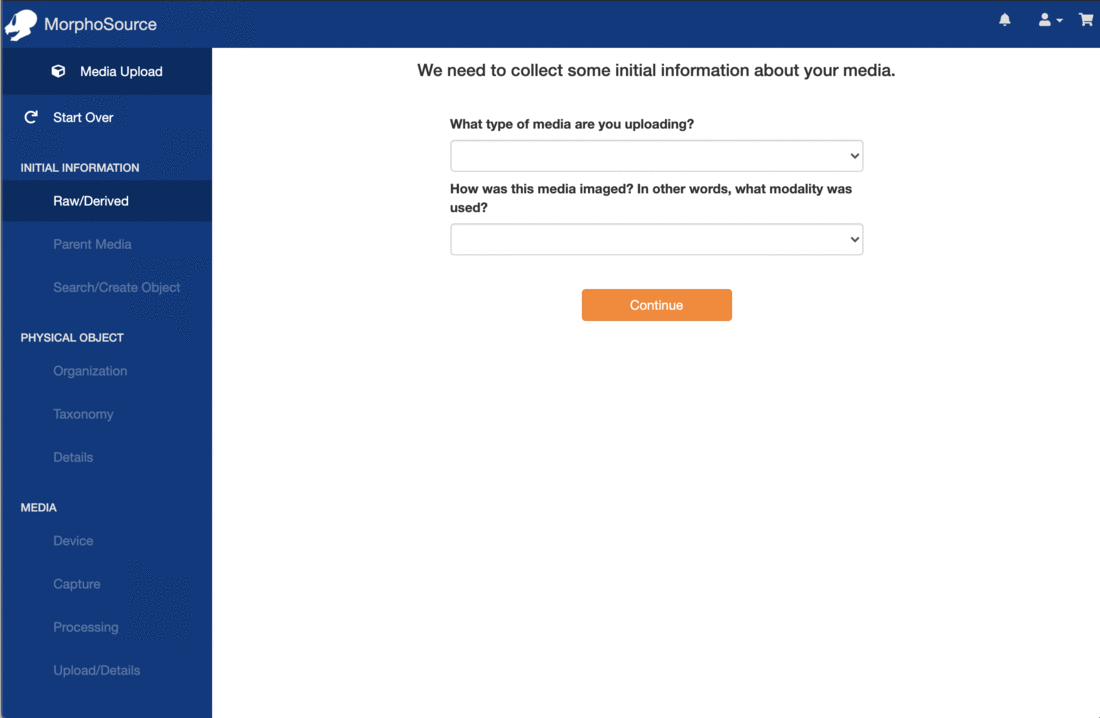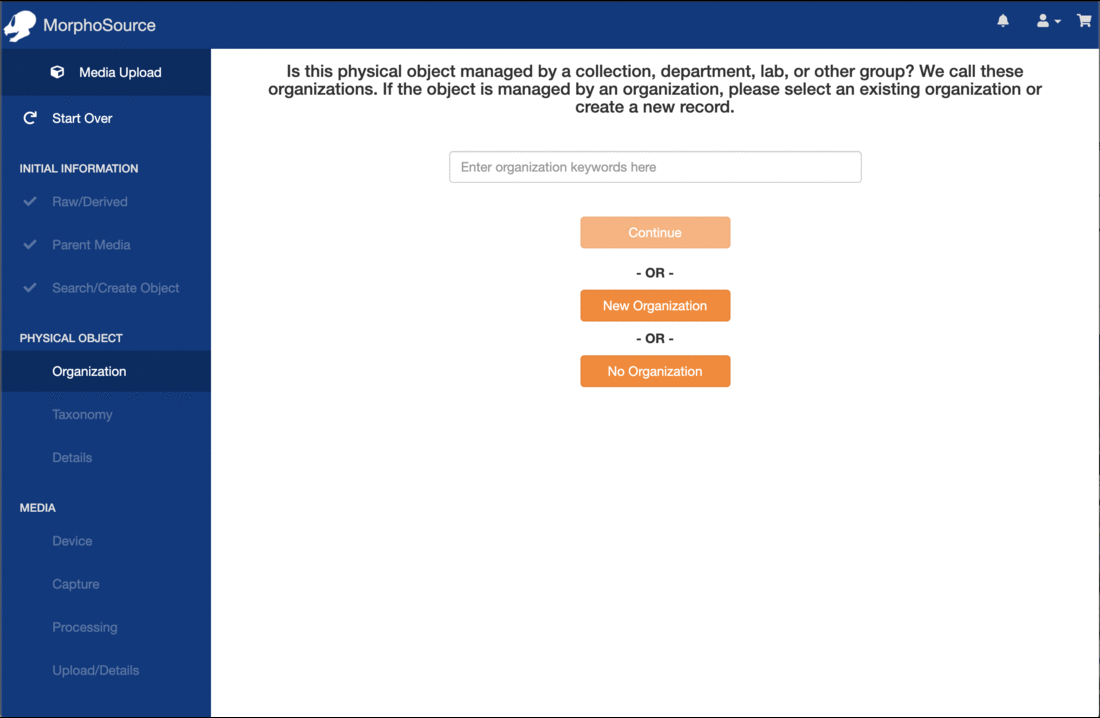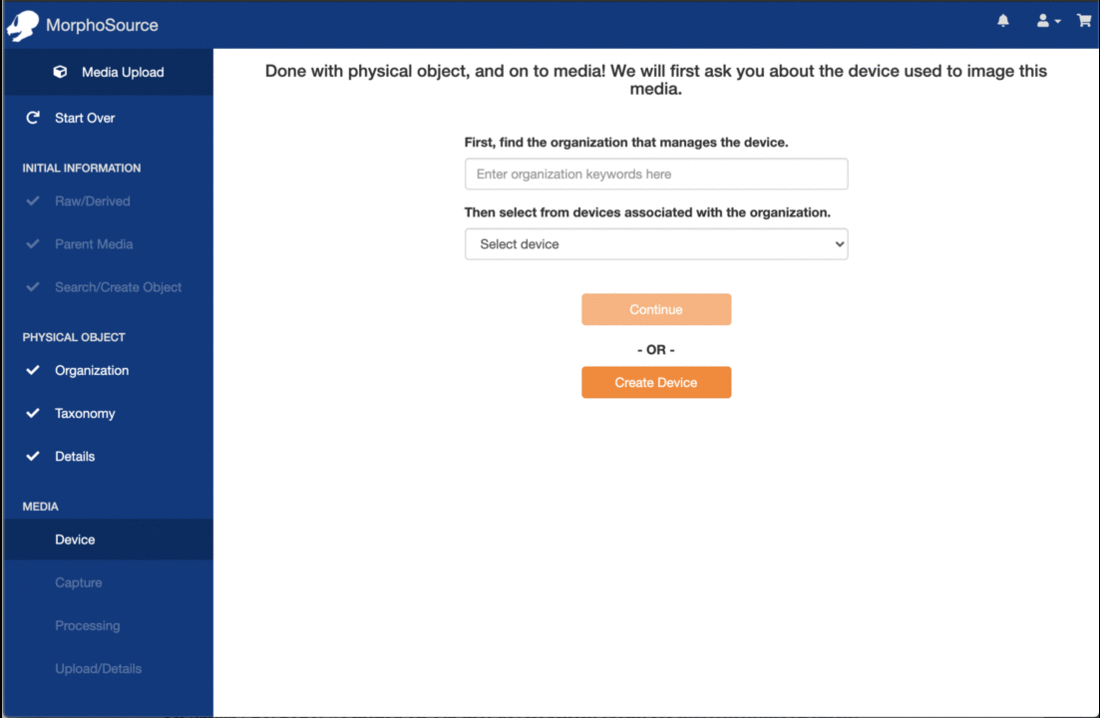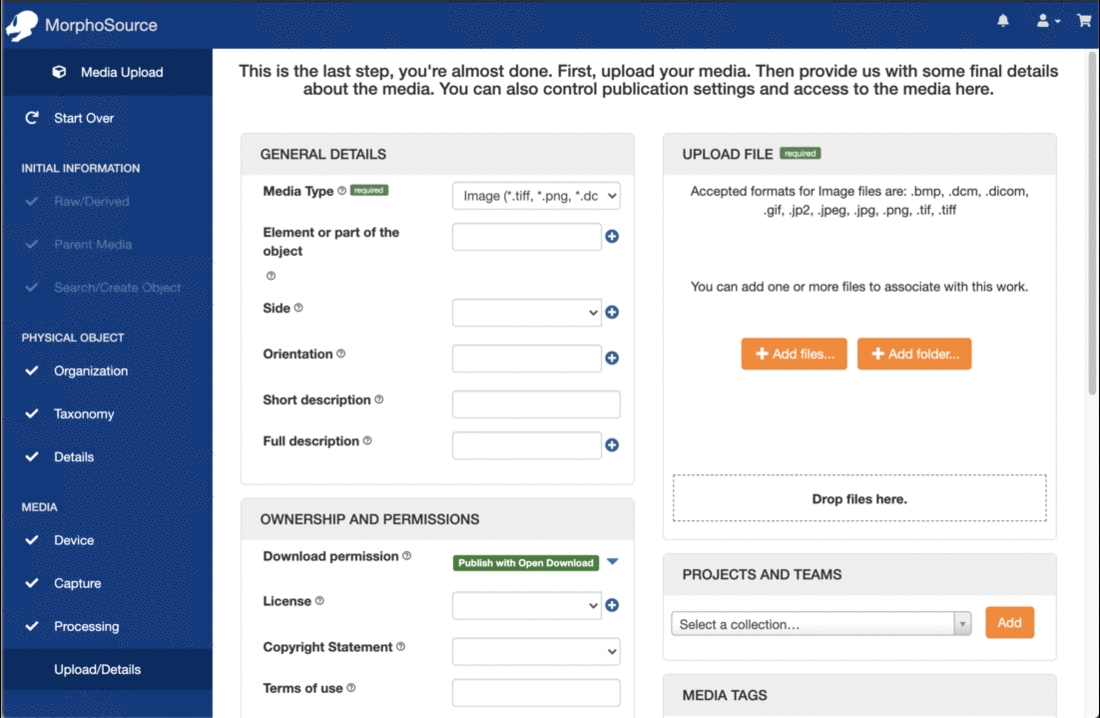
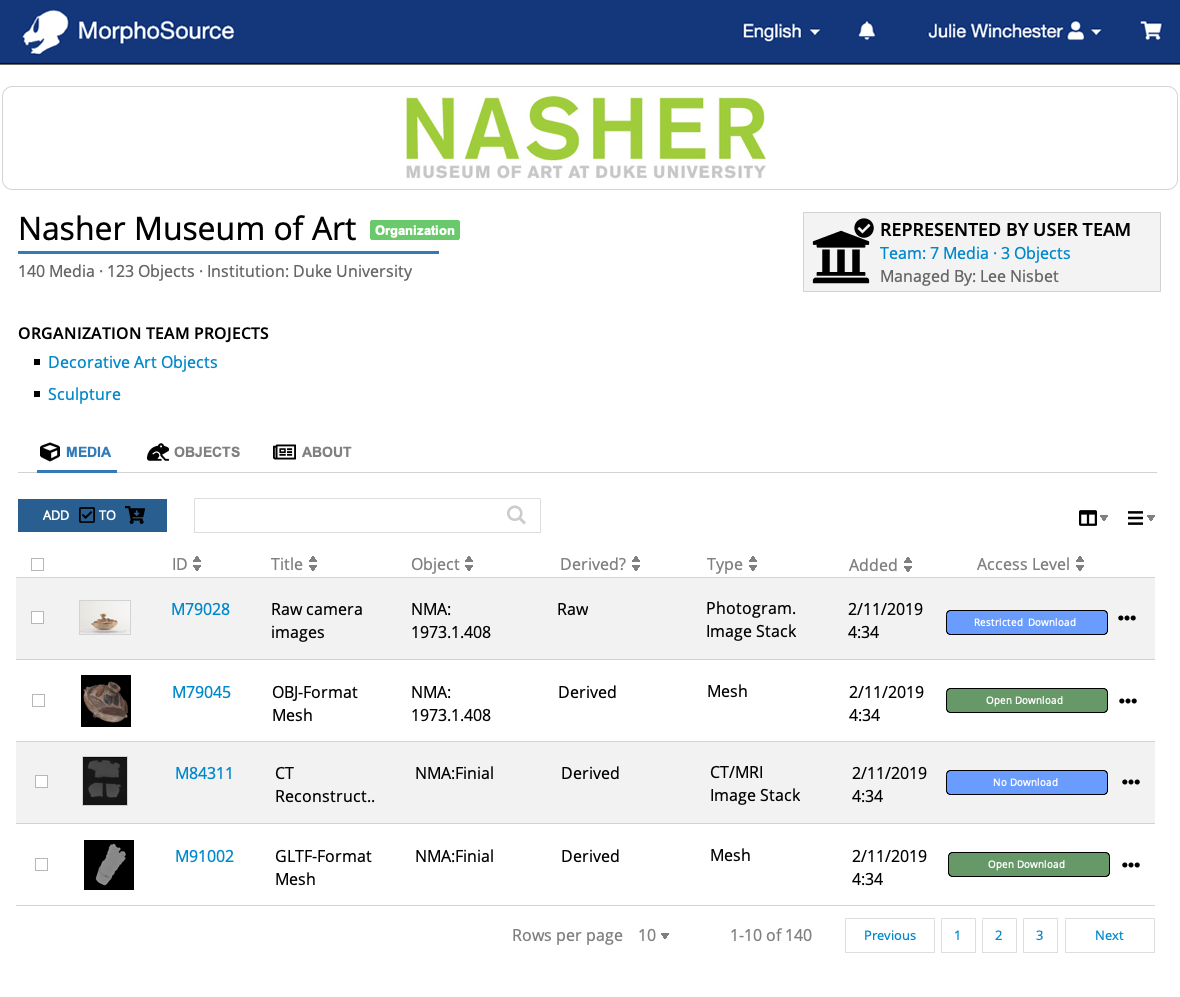
Organizations: Lastly, users can view all of the organizations that have biological specimens or cultural heritage objects in MorphoSource. An organization may be an institution, department, collection, facility, lab, or other group. From the Organizations browse page, users can search by name and sort by parent institution name or institution code.
Faceted Searching
In addition to the browse pages, records for Media, Biological Specimens, Cultural Heritage Objects, Organizations, Teams, and Projects can also be found through the MorphoSource search interface. Searching has been customized for the different record types to include relevant facets. The different search categories can be chosen from the dropdown next to the search box ‘Go’ button.
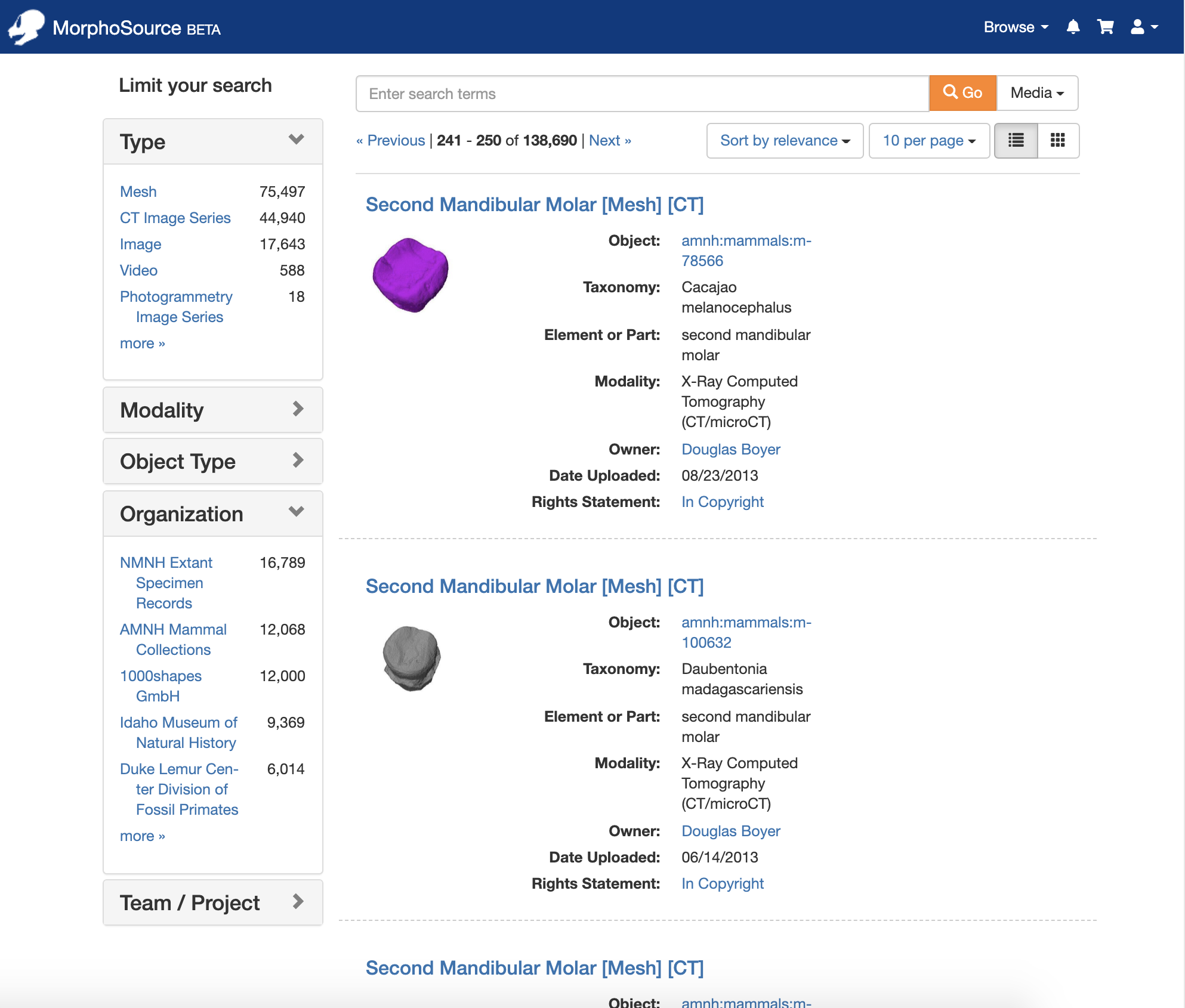
Search results for media records can be faceted by file type, modality, object type (biological specimen or cultural heritage object), organization, tag, or membership in a team or project, while search results for objects can be limited by object type, creator, organization, taxonomy, associated media types, associated media tags, and membership of associated media in a team or project. Organization and Team/Project searches similarly have their own sets of facets.

User Dashboards
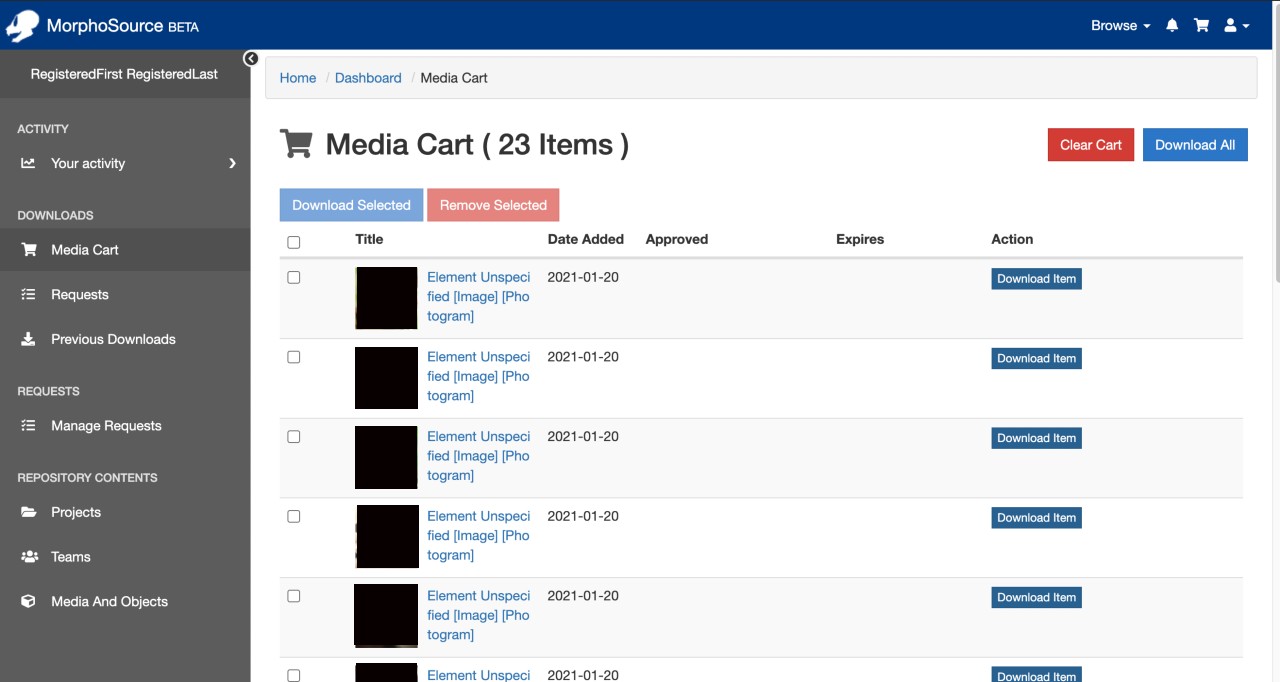
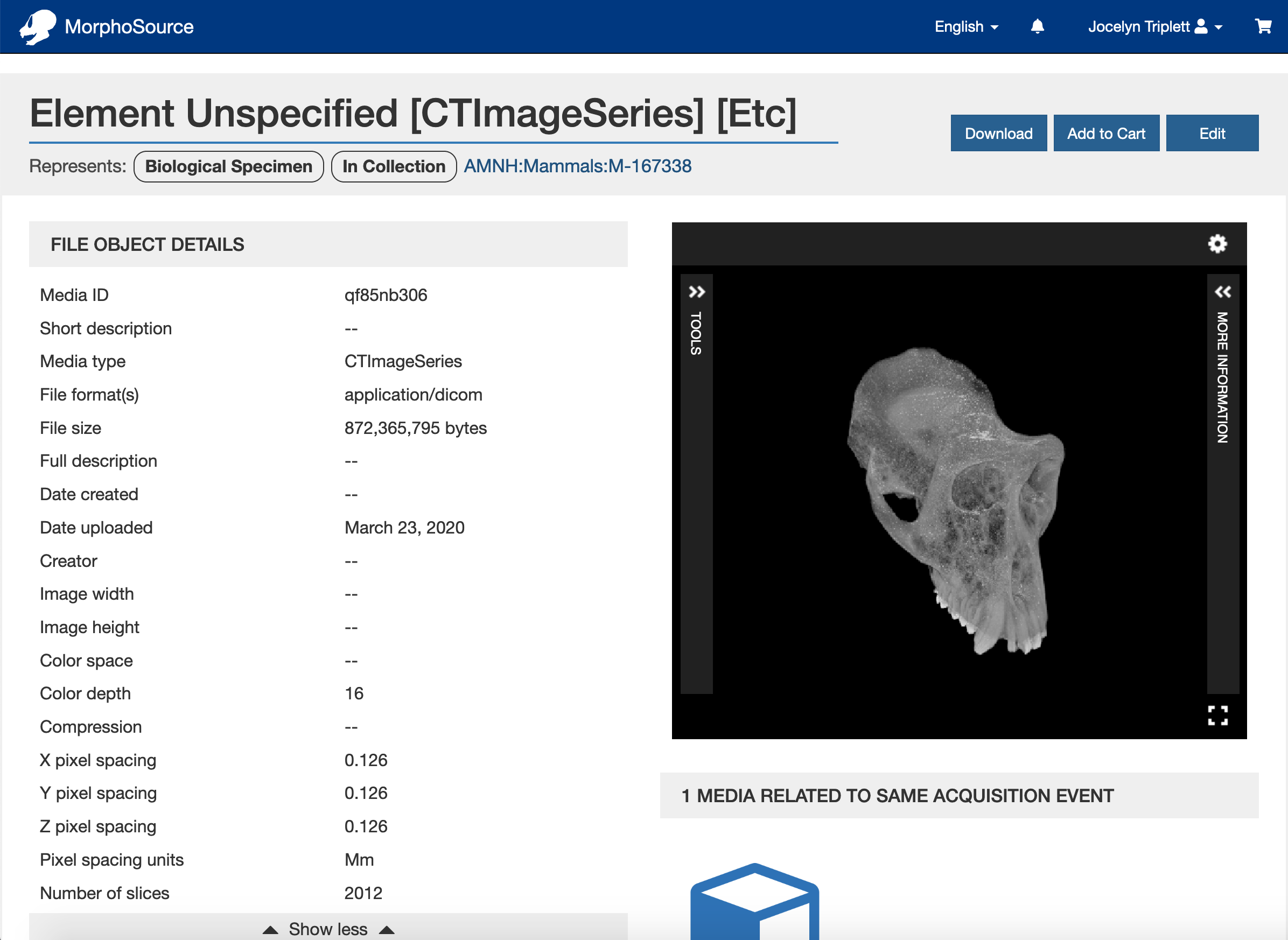
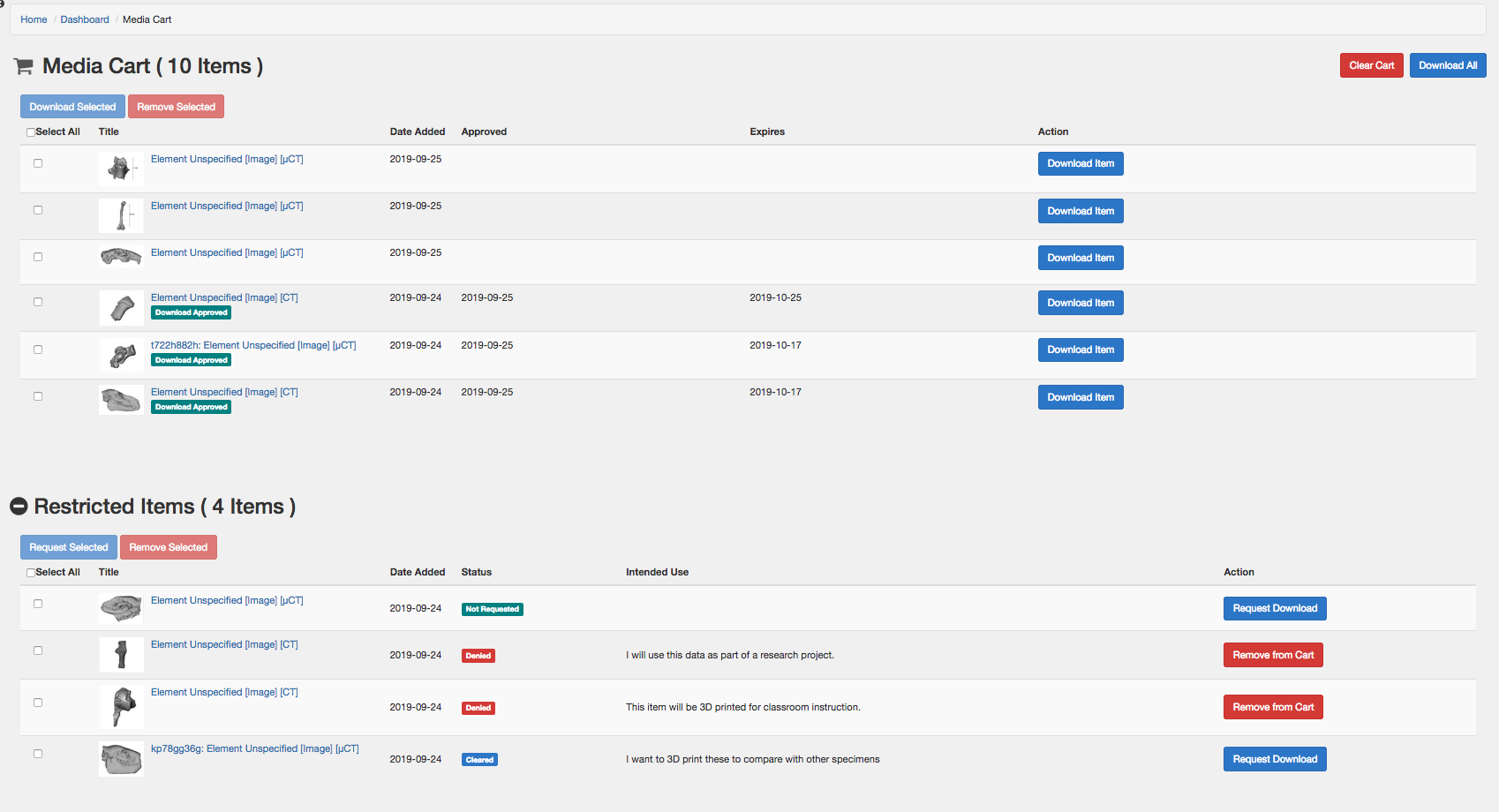
Users who register an account on the site will have access to a dashboard that enables them to manage their data downloads. The dashboard is accessed by clicking on the profile icon at the top right of the site, and will open to the user’s media cart. The media cart contains two sections – the top holds all media items that the user currently has permission to download, while the bottom has media items with a restricted status where download has not been requested or approved:
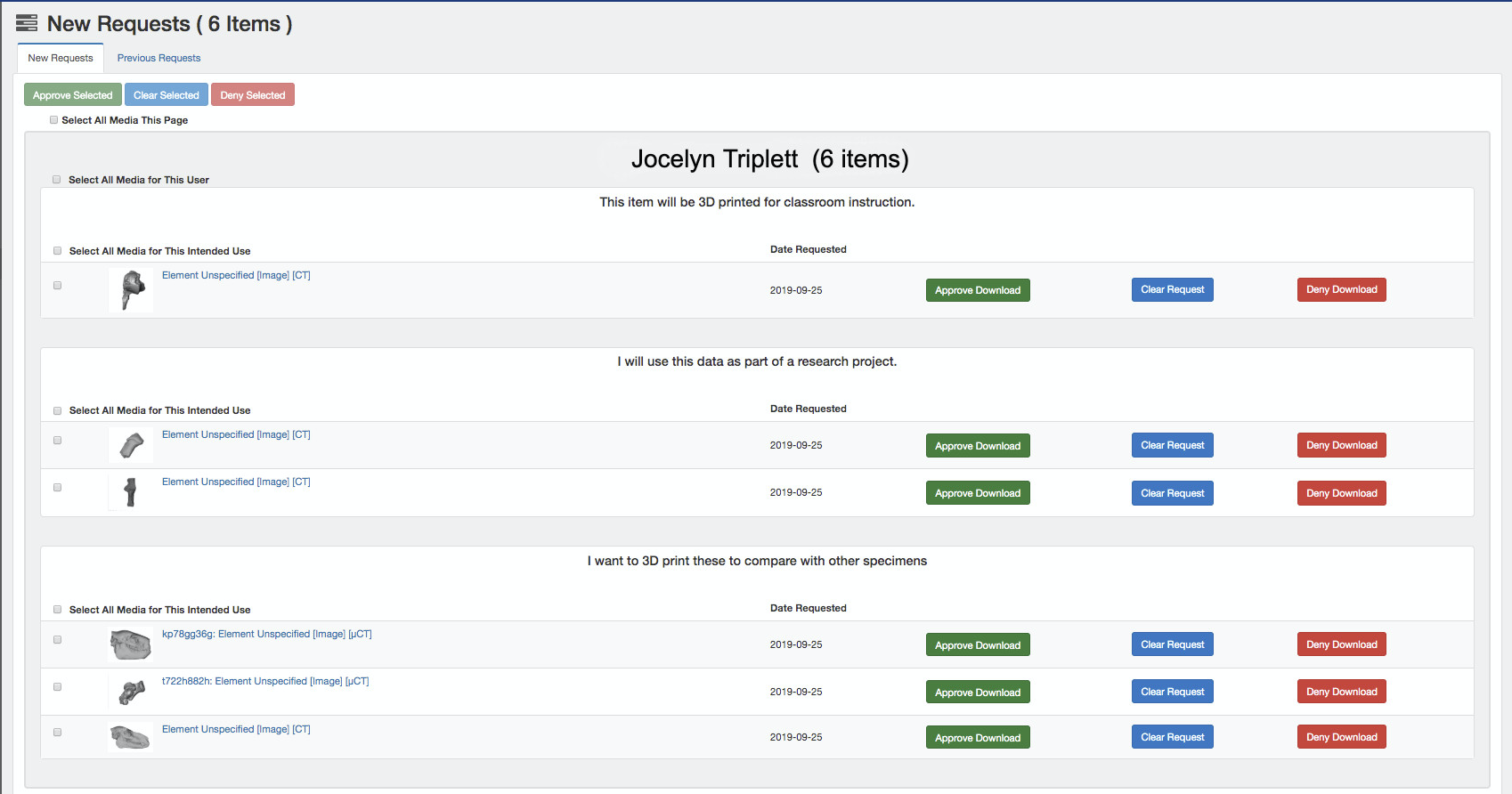
Users who have been granted contributor access to the site will have a dashboard that opens to the media and objects that they have contributed:
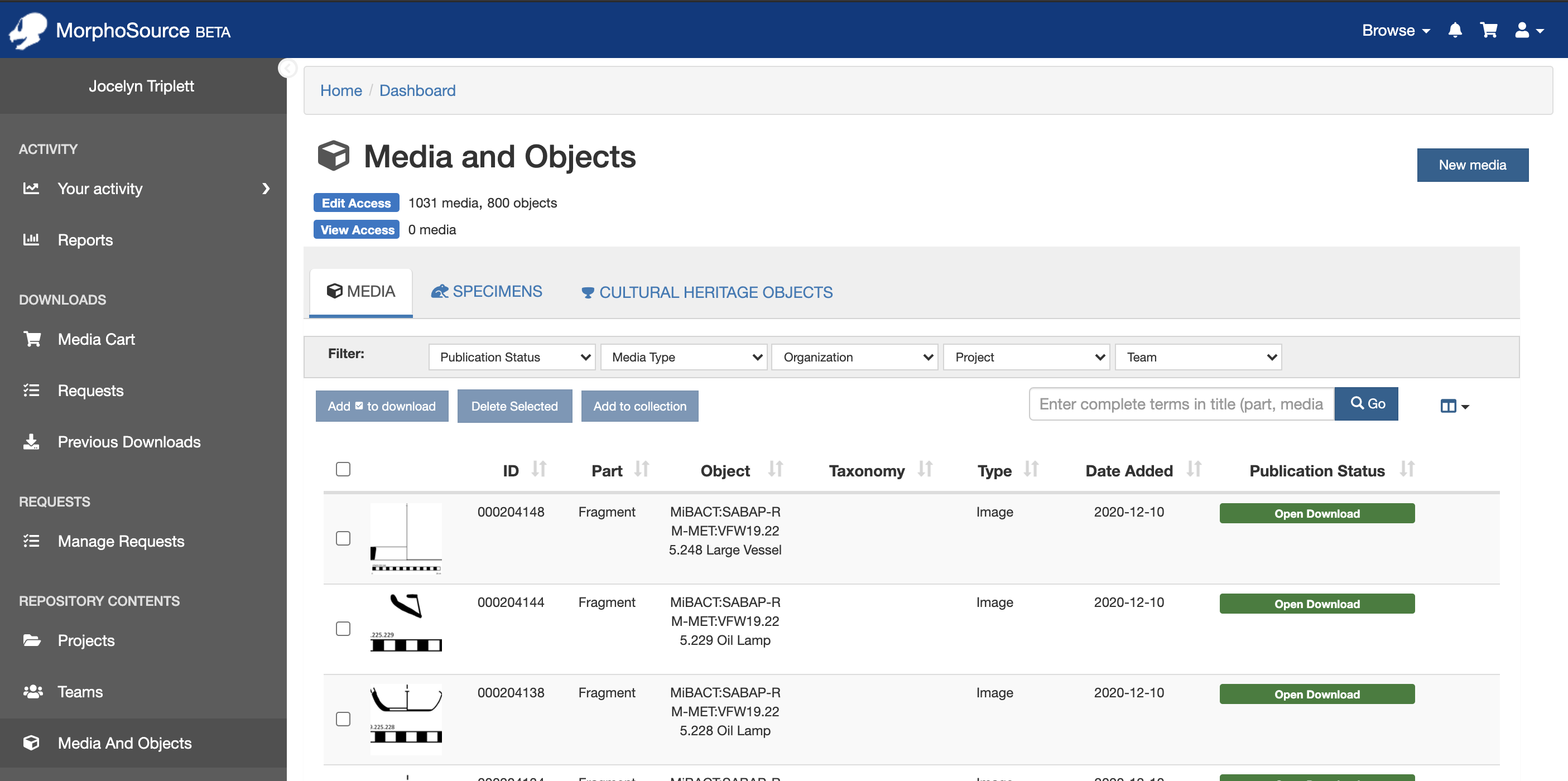
From the menu at the left, all users can access their previous downloads, or projects, teams, or other repository content to which they have been granted access, and manage their user profile. In addition, contributors can also create and manage projects and teams.
We hope that the browse, search, and dashboard enhancements, along with the other features we have been working on over the last couple of years, will enable users to easily discover and manage data sets in MorphoSource. And although we are looking forward to the launch, we are also excited to continue working on the site, and will be adding even more features in the near future.


 Header Image: Collection of extinct and extant turtle skull microCT scans in MorphoSource:
Header Image: Collection of extinct and extant turtle skull microCT scans in MorphoSource: