
Abstract
In this work, we first replicate the results of the fully parametric dynamic probit model for forecasting US recessions from Kauppi and Saikkonen (Rev Econ Stat 90(4):777–791, 2008) [which is in the spirit of Estrella and Mishkin (Rev Econ Stat 80(1):45–61, 1998) and Dueker (Rev Fed Reserve Bank St Louis 79(2):41–51, 1997)] and then contrast them to results from a nonparametric local-likelihood dynamic choice model for the same data. We then use expanded data to gain insights on whether these models could have warned the public about approach of the latest recession, associated with the Global Financial Crisis. Finally, we also apply both approaches to gain insights for 2018.





Similar content being viewed by others

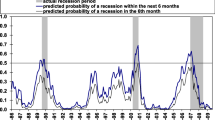
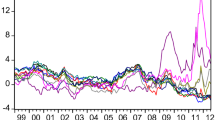
Notes
We use the following convention for the notation: capital letter (e.g., \(Y_{t}\)) denotes an unobserved random variable in the time period t, while the fixed values it can or do take or points at which one want to estimate are denoted with small letters (e.g., y or \(y_{t}\) if the timing of the observation is to be emphasized).
Specifically, we note that \(Q(\cdot ,y_{t})\) is defined by \(\partial Q(\mu ,y_{t})/\partial \mu =(y_{t}-\mu )/V(\mu )\), where V is a chosen function for the working conditional variance model; see Park et al. (2017) and Li et al. (2016) for more of the technical details for the methodology used in this paper.
Here, it is also worth noting that although the implementation requires the choice of the link function (e.g., probit), the theory in Park et al. (2017) suggests that the asymptotic properties of the estimators are largely independent on the choice of g as long as it is sufficiently smooth and strictly increasing, because the estimation is performed locally.
For example, see a nice survey on related discussion by Florio (2004).
As correctly pointed out by a referee, the observed curvature could also be due to estimation uncertainty and so the statistical testing (yet to be developed in this framework) is needed to confirm or reject it with greater certainty.
Such a comparison appears reasonable at least heuristically, although rigorous theory needs to be developed to justify this or other comparisons of parametric and nonparametric fits in the context of dynamic discrete choice modeling and forecasting.
Here, the new optimal bandwidths were re-estimated with each addition to the sample, to account for the new information and for the new sample size.
Clearly, these values generally depend on the cutoff between the estimation subsample and the forecast validation, and so, we also varied the cutoff point and confirmed the general conclusion is robust, with the similarity increasing when the estimation sample is decreasing.
e.g., see Temin (2010) for discussions about this period.
For example, the warnings about the looming crisis from Nouriel Roubini are often referred to September 2006, yet it appears they were not taken seriously by many before the collapse of Lehman Brothers, and even less so before another top five investment bank, Bear Sterns, collapsed in March 2008. For example, see the article ‘Dr. Doom”’ , by S. Mihm in New York Times Magazine (15 August 2008).
In principle, one can also use the two-periods ahead forecasts as those discussed in the previous section (and we did so and obtained the same conclusion) or construct k-periods ahead forecasts, or a combination of these approaches with various weights, or try different thresholds besides 0.5—the many possible exercises we leave for future explorations.
The new optimal bandwidths were re-estimated at each iteration to account for the new information and for the new sample size.
Interestingly, note that the two-periods ahead forecasts gave stronger warnings about the looming recession than the one-period ahead forecasts, as well as did so earlier.
It might be also worth noting here that the NBER’s Business Cycle Dating Committee also met in April 2010 but without a decision, concluding: ‘Although most indicators have turned up, the committee decided that the determination of the trough date on the basis of current data would be premature...”.
On average, NBER’s decisions came with about 11 months delay (if counting since 1979 when they started the formal announcements of business cycle turning points). The longest delays, 20 and 19 months, were to announce the troughs of 1991 and 2001, yet there is no guarantee that the NBER does not take longer delay to announce the new peak that ends the latest expansion.
As correctly pointed out by the referee, rigorous comparisons of the two approaches should also consider the measures of random variation and accuracy of estimates, which are yet to be developed for this framework.
In principle, one can use Theorem 3.1 of Park et al. (2017) to construct a point-wise confidence intervals. However, this requires the estimation of more complex functions such as the second derivatives of the index function. Instead, one may apply a bootstrap method to construct confidence bands, though one also need to check whether the bootstrap method works theoretically and how good it performs in small samples.
According to NBER, the only two longer expansions in the USA since 1854 were those between March 1991 and March 2001 (120 months) and between February 1961 and December 1969 (106 months), while the average was only about 39 months overall (over 33 business cycles, since 1854) and about 58 months since 1945 (over 11 business cycles).
References
Aitchison J, Aitken CGG (1976) Multivariate binary discrimination by the kernel method. Biometrika 63(3):413–420
Chu CY, Henderson DJ, Parmeter CF (2015) Plug-in bandwidth selection for kernel density estimation with discrete data. Econometrics 3(2):199–214
Dueker M (1997) Strengthening the case for the yield curve as a predictor of U.S. recessions. Rev Fed Reserve Bank St Louis 79(2):41–51
Efron B (1978) Regression and ANOVA with zero-one data: measures of residual variation. J Am Stat Assoc 73:113–121
Estrella A (1998) A new measure of fit for equations with dichotomous dependent variables. J Bus Econ Stat 16(2):198–205
Estrella A, Mishkin FS (1995) Predicting U.S. recessions: financial variables as leading indicators. Working paper 5379, National Bureau of Economic Research
Estrella A, Mishkin FS (1998) Predicting U.S. recessions: financial variables as leading indicators. Rev Econ Stat 80(1):45–61
Fan J, Heckman NE, Wand MP (1995) Local polynomial kernel regression for generalized linear models and quasi-likelihood functions. J Am Stat Assoc 90:141–150
Florio A (2004) The Asymmetric Effects of Monetary Policy. J Econ Surv 18:409–426
Henderson DJ, Parmeter CF (2015) Applied nonparametric econometrics. Cambridge University Press, Cambridge
Kauppi H, Saikkonen P (2008) Predicting U.S. recessions with dynamic binary response models. Rev Econ Stat 90(4):777–791
Li D, Simar L, Zelenyuk V (2016) Generalized nonparametric smoothing with mixed discrete and continuous data. Comput Stat Data Anal 100:424–444
Park BU, Simar L, Zelenyuk V (2017) Nonparametric estimation of dynamic discrete choice models for time series data. Comput Stat Data Anal 108:97–120
Temin P (2010) The Great Recession and the Great Depression. National Bureau of Economic Research (NBER), Working paper no. 15645
Acknowledgements
We thank Adrian Pagan, colleagues and participants of various events where earlier versions of this work was presented for their valuable feedback. We acknowledge and thank for the financial support provided by the ARC Discovery Grant (DP130101022) and ARC FT170100401, from the ‘Interuniversity Attraction Pole’, Phase VII (No. P7/06) of the Belgian Science Policy, and the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIP) (No. NRF-2014R1A4A1007895). We also thank Ms. Ailin Leng for her technical assistance with some data collection at the early stage of the project. Finally, we thank the editor and two anonymous referees for the fruitful feedback that helped improving this paper substantially.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Park, B.U., Simar, L. & Zelenyuk, V. Forecasting of recessions via dynamic probit for time series: replication and extension of Kauppi and Saikkonen (2008). Empir Econ 58, 379–392 (2020). https://doi.org/10.1007/s00181-019-01708-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00181-019-01708-2