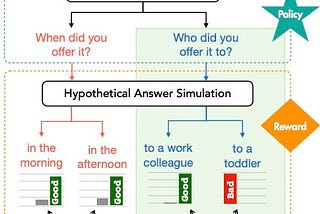
AI2RewardBench: the first benchmark & leaderboard for reward models used in RLHFWe introduce RewardBench, a benchmark for evaluating preference reward models. We test the limits of reward models on everything including…5 min read·Mar 20, 2024----
AI2AI2 at EMNLP 2023Highlighted work from our institute appearing at this year’s EMNLP conference7 min read·Dec 4, 2023----
Joseph Chee ChangAI2 at ACM UIST 2023New Intelligent Reading Interfaces Research and The Semantic Reader Open Research Platform5 min read·Oct 30, 2023----
Bill Yuchen Lin, PhDSwiftSage: Building AI Agents for Complex Interactive Tasks via Fast and Slow Thinking with LLMsSwiftSage, a novel AI agent inspired by fast-and-slow thinking, designed to optimize LLMs for planning for complex interactive tasks.5 min read·Jun 21, 2023----
Maria AntoniakUsing Large Language Models With CareHow to be mindful of current risks when using chatbots and writing assistants11 min read·Jun 19, 2023--2--2
Valentina PyatkinClarifyDelphiReinforced Clarification Questions with Defeasibility Rewards for Social and Moral Situations5 min read·May 30, 2023----
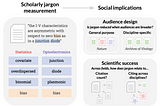
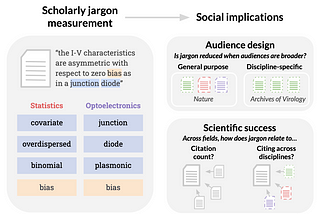
Lucy LiWords as Gatekeepers: Measuring Discipline-specific Terms and Meanings in Scholarly PublicationsScholarly text is often laden with jargon, or specialized language that can facilitate efficient communication within fields but hinder…3 min read·May 8, 2023--1--1
AI2AI2 at CHI 2023Highlighted work from our institute appearing at this year’s CHI conference5 min read·Apr 22, 2023----
Tanmay GuptaVisual ProgrammingAI that solves computer vision tasks by writing code10 min read·Mar 16, 2023--1--1
Jon Saad-FalconEmbedding RecyclingMaking Language Model Development More Sustainable3 min read·Feb 15, 2023----