In T228500: Toolforge: evaluate ingress mechanism we discussed several setups for the north-south traffic and proxy setup. With north-south I mean traffic between end users (internet) and the pod containing the tool webservice.
Related things to decide:
- Do we want to introduce $tool.$domain.org yes or not. My feeling is yes. Also, if we introduce this pattern, do it only for toolforge.org
- Do we want to introduce toolforge.org yes or not. My feeling is that yes.
- Will the legacy k8s be aware of the 2 things above? i.e, would we introduce either $tool.$domain.org or toolforge.org/$tool in the old k8s deployment. My feeling is that we don't want this, as will be a lot of work that will only be valid for the compat/migration period between k8s deployments.
- Will the web grid be aware of the things above? i.e, would we introduce either $tool.$domain.org or toolforge.org/$tool in the web grid. My feeling is that this can be done later after the new k8s is already in place.
- SSL termination
Will try to summarize here the different options:
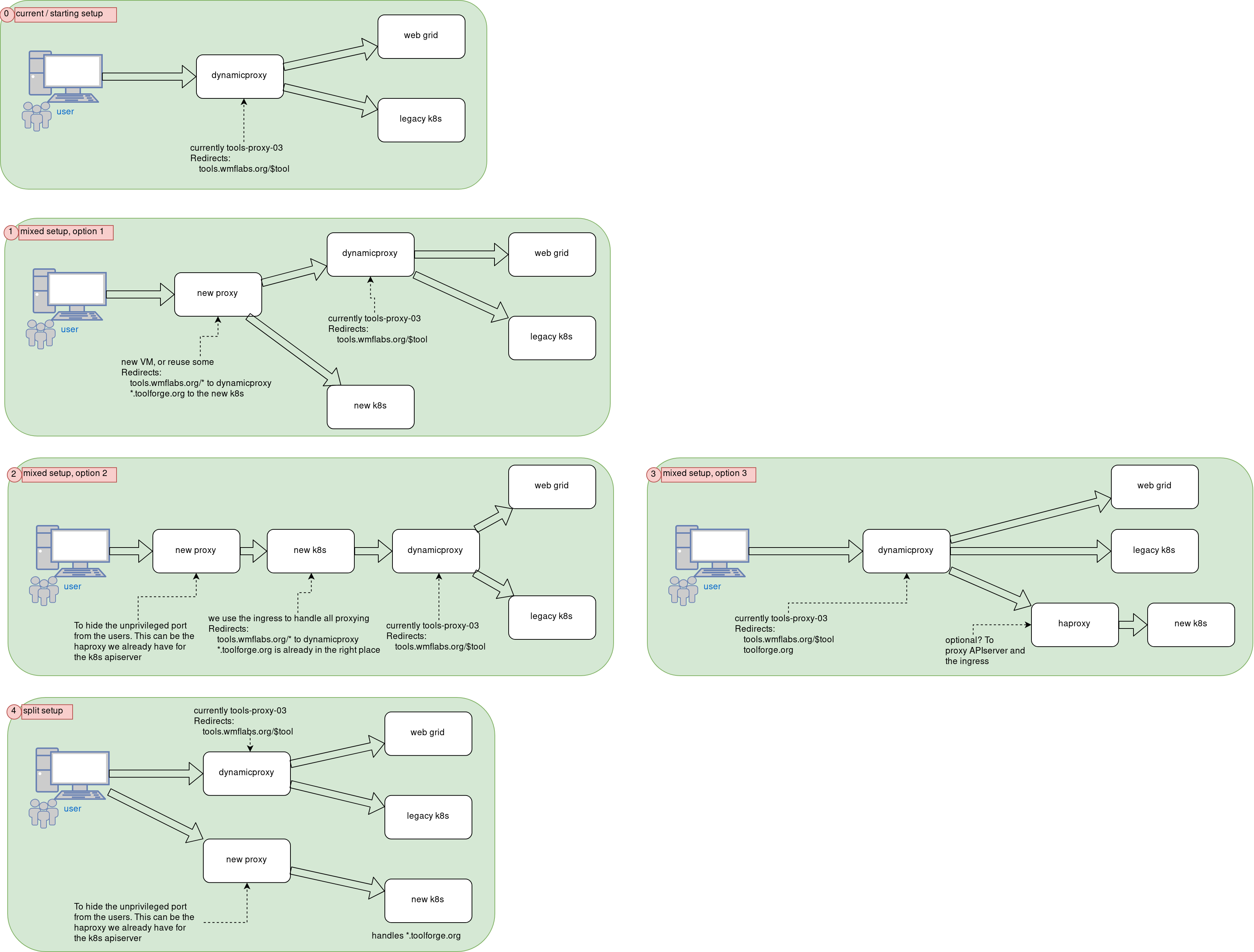
Diagram 0: the current setup. Dynamicproxy redirects tools.wmflabs.org/$tool to the right backend (be it the web grid or the legacy k8s).
Diagram 1: we introduce a new proxy in front of both the current setup and the new k8s. This proxy knows how to redirect *.toolforge.org to the new k8s and tools.wmflabs.org/$tool to dynamicproxy.
Diagram 2: the new k8s acts as proxy for the current setup, by means of the ingress. We can create an ingress rule to redirect all tools.wmflabs.org/$tool traffic to dynamicproxy
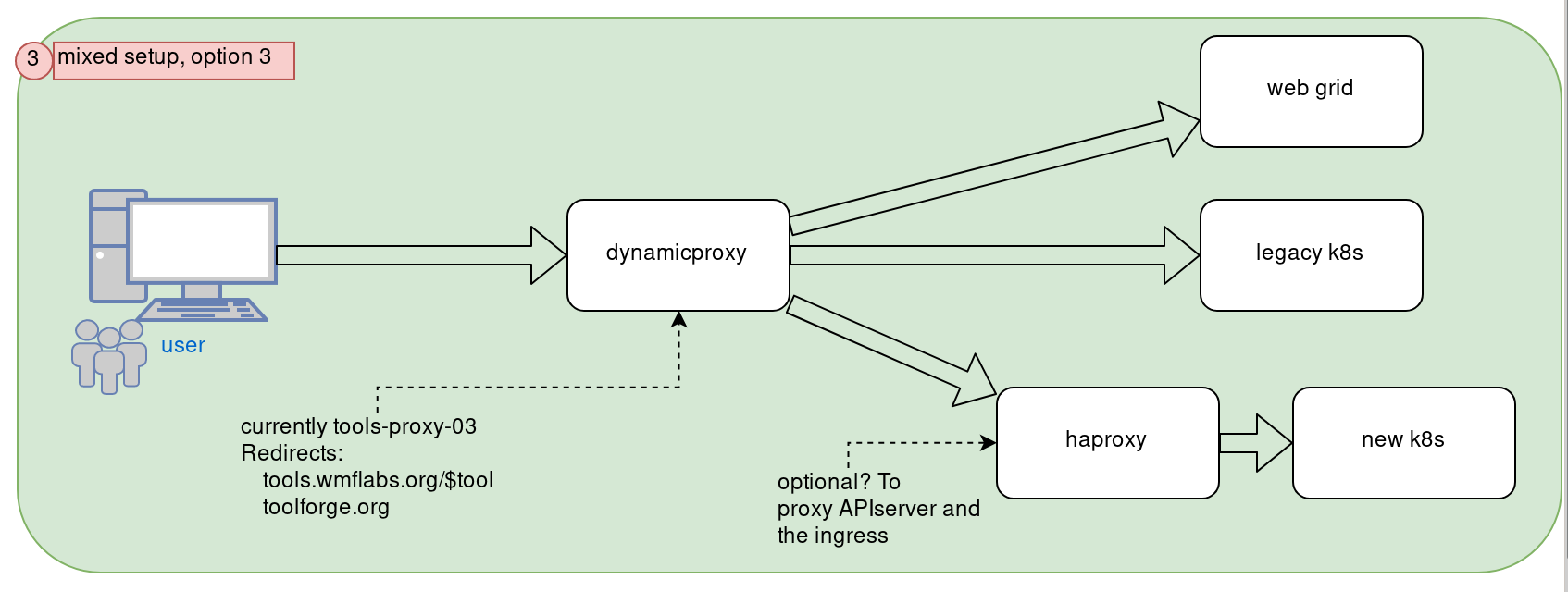
Diagram 3: proposed by @bd808 we update dynamicproxy to be in from of both the legacy setup and the new k8s.
Diagram 4: split setup. The current setup and the new k8s are totally separated. This is perhaps the most simple setup.