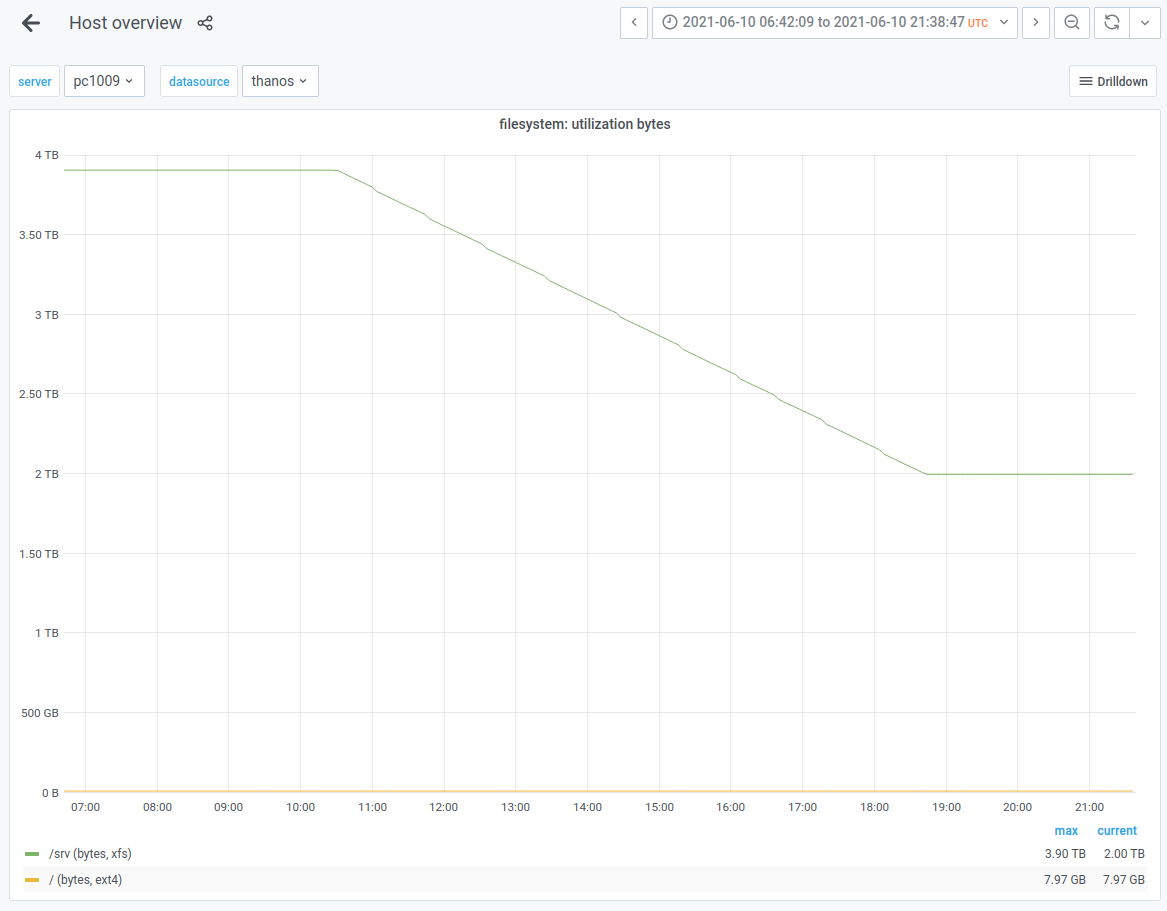
This follows-up from T280605#7070345
Background
This purgeParserCache.php script is scheduled to run every night, to prune ParserCache blobs that then are beyond their expiry date. Our blobs generally have an expiry date of 30 days, which means we expect this nightly run will remove the blobs we stored roughly 30 days ago on that day.
Problem
As of writing, the purge script now takes over a week to complete a single run. This has numerous consequences:
- Due to taking 10 days to run, we are effectively having to accomodate blobs for upto 37 days rather than 30-31 days. This means more space is occupied by default.
- Each run is taking longer than the last. This means the backlog is growing, and thus the space consumption as well. E.g. I expect we'll soon be accomodating blobs for 40 days, etc. There is no obvious end, other than a full disk.
- With the backlog growing, the run will take even longer, as it has to iterate more blobs to purge them. See point 2.
What we know
The script ran daily up until 19 April 2020 (last year):
- 19 April 2020: Run took 1 day (the last time this happened).
- 24 April 2020: Run took 3 days.
- 26 Jun 2020: Run took 4 days.
- 28 Nov 2020: Run took 6 days.
- 13 Apr 2021: Run took 7 days.
- 7 May 2021: Run was aborted after 5 days during which it completed 81% (2 May 01:51 - 7 May 05:23)
- 13 May 2021: The current is at 26% which has taken 116 hours so far (May 7 05:23 - May 13 01:42). Extrapolating I would expect 446 hours in total, or 18 days?
(Caveat: The script's percentage meter assumes all shards are equal which they probably aren't.)
The script iterates over each parser cache database host, then each parser cache table on that host, and then selects/deletes in batches of 100 rows with a past expiry date. (code 1, code 2). It waits for a 500 ms sleep between each such batch.
This sleep was introduced in 2016 to mitigate T150124: Parsercache purging can create lag.
In 2016, the first mitigation used 100ms, which was then increased to 500ms.
Note that this task is not about product features adding more blobs to the ParserCache in general. I believe as it stands, the problem this task is about, will continue to worses even if our demand remains constant going forward. However, that increased demand in the last 12 months (see T280605) has pushed us over an invisible tipping point that has cascaded into this self-regressing situation.
Data
| 1 | # [19:15 UTC] krinkle at mwmaint1002.eqiad.wmnet in /var/log/mediawiki/mediawiki_job_parser_cache_purging |
|---|---|
| 2 | # $ fgrep "Deleting" syslog.log |
| 3 | Apr 10 01:00:03 mwmaint1002 mediawiki_job_parser_cache_purging[146571]: Deleting objects expiring before 01:00, 10 April 2020 |
| 4 | Apr 11 03:56:45 mwmaint1002 mediawiki_job_parser_cache_purging[240365]: Deleting objects expiring before 03:56, 11 April 2020 |
| 5 | Apr 12 08:12:32 mwmaint1002 mediawiki_job_parser_cache_purging[72089]: Deleting objects expiring before 08:12, 12 April 2020 |
| 6 | Apr 13 07:29:56 mwmaint1002 mediawiki_job_parser_cache_purging[2846]: Deleting objects expiring before 07:29, 13 April 2020 |
| 7 | Apr 14 02:38:09 mwmaint1002 mediawiki_job_parser_cache_purging[210524]: Deleting objects expiring before 02:38, 14 April 2020 |
| 8 | Apr 15 01:00:03 mwmaint1002 mediawiki_job_parser_cache_purging[83431]: Deleting objects expiring before 01:00, 15 April 2020 |
| 9 | Apr 16 01:00:06 mwmaint1002 mediawiki_job_parser_cache_purging[66915]: Deleting objects expiring before 01:00, 16 April 2020 |
| 10 | Apr 17 01:15:19 mwmaint1002 mediawiki_job_parser_cache_purging[12688]: Deleting objects expiring before 01:15, 17 April 2020 |
| 11 | Apr 18 01:00:01 mwmaint1002 mediawiki_job_parser_cache_purging[204947]: Deleting objects expiring before 01:00, 18 April 2020 |
| 12 | Apr 19 13:07:02 mwmaint1002 mediawiki_job_parser_cache_purging[182094]: Deleting objects expiring before 13:07, 19 April 2020 |
| 13 | Apr 21 20:59:35 mwmaint1002 mediawiki_job_parser_cache_purging[250916]: Deleting objects expiring before 20:59, 21 April 2020 |
| 14 | Apr 24 19:47:46 mwmaint1002 mediawiki_job_parser_cache_purging[101035]: Deleting objects expiring before 19:47, 24 April 2020 |
| 15 | Apr 27 23:09:18 mwmaint1002 mediawiki_job_parser_cache_purging[206784]: Deleting objects expiring before 23:09, 27 April 2020 |
| 16 | Apr 30 16:53:08 mwmaint1002 mediawiki_job_parser_cache_purging[205448]: Deleting objects expiring before 16:53, 30 April 2020 |
| 17 | May 3 00:37:27 mwmaint1002 mediawiki_job_parser_cache_purging[42048]: Deleting objects expiring before 00:37, 3 May 2020 |
| 18 | May 5 05:13:29 mwmaint1002 mediawiki_job_parser_cache_purging[20388]: Deleting objects expiring before 05:13, 5 May 2020 |
| 19 | May 7 16:30:25 mwmaint1002 mediawiki_job_parser_cache_purging[19386]: Deleting objects expiring before 16:30, 7 May 2020 |
| 20 | May 9 21:54:40 mwmaint1002 mediawiki_job_parser_cache_purging[259760]: Deleting objects expiring before 21:54, 9 May 2020 |
| 21 | May 12 03:47:45 mwmaint1002 mediawiki_job_parser_cache_purging[13882]: Deleting objects expiring before 03:47, 12 May 2020 |
| 22 | May 14 04:12:29 mwmaint1002 mediawiki_job_parser_cache_purging[164959]: Deleting objects expiring before 04:12, 14 May 2020 |
| 23 | May 16 02:39:31 mwmaint1002 mediawiki_job_parser_cache_purging[32112]: Deleting objects expiring before 02:39, 16 May 2020 |
| 24 | May 18 02:41:09 mwmaint1002 mediawiki_job_parser_cache_purging[196859]: Deleting objects expiring before 02:41, 18 May 2020 |
| 25 | May 20 07:12:25 mwmaint1002 mediawiki_job_parser_cache_purging[167348]: Deleting objects expiring before 07:12, 20 May 2020 |
| 26 | May 22 13:35:47 mwmaint1002 mediawiki_job_parser_cache_purging[186721]: Deleting objects expiring before 13:35, 22 May 2020 |
| 27 | May 25 06:03:37 mwmaint1002 mediawiki_job_parser_cache_purging[149790]: Deleting objects expiring before 06:03, 25 May 2020 |
| 28 | May 28 13:49:01 mwmaint1002 mediawiki_job_parser_cache_purging[190184]: Deleting objects expiring before 13:49, 28 May 2020 |
| 29 | Jun 1 05:22:29 mwmaint1002 mediawiki_job_parser_cache_purging[41516]: Deleting objects expiring before 05:22, 1 June 2020 |
| 30 | Jun 3 14:01:01 mwmaint1002 mediawiki_job_parser_cache_purging[161911]: Deleting objects expiring before 14:01, 3 June 2020 |
| 31 | Jun 5 23:24:21 mwmaint1002 mediawiki_job_parser_cache_purging[19792]: Deleting objects expiring before 23:24, 5 June 2020 |
| 32 | Jun 9 18:49:46 mwmaint1002 mediawiki_job_parser_cache_purging[228933]: Deleting objects expiring before 18:49, 9 June 2020 |
| 33 | Jun 13 06:37:17 mwmaint1002 mediawiki_job_parser_cache_purging[33396]: Deleting objects expiring before 06:37, 13 June 2020 |
| 34 | Jun 16 06:29:11 mwmaint1002 mediawiki_job_parser_cache_purging[84032]: Deleting objects expiring before 06:29, 16 June 2020 |
| 35 | Jun 19 06:14:53 mwmaint1002 mediawiki_job_parser_cache_purging[92680]: Deleting objects expiring before 06:14, 19 June 2020 |
| 36 | Jun 22 17:19:58 mwmaint1002 mediawiki_job_parser_cache_purging[88936]: Deleting objects expiring before 17:19, 22 June 2020 |
| 37 | Jun 26 11:15:00 mwmaint1002 mediawiki_job_parser_cache_purging[156464]: Deleting objects expiring before 11:15, 26 June 2020 |
| 38 | Jun 30 09:46:00 mwmaint1002 mediawiki_job_parser_cache_purging[205484]: Deleting objects expiring before 09:46, 30 June 2020 |
| 39 | Jul 3 17:42:57 mwmaint1002 mediawiki_job_parser_cache_purging[221089]: Deleting objects expiring before 17:42, 3 July 2020 |
| 40 | Jul 6 21:08:00 mwmaint1002 mediawiki_job_parser_cache_purging[119347]: Deleting objects expiring before 21:08, 6 July 2020 |
| 41 | Jul 9 17:05:20 mwmaint1002 mediawiki_job_parser_cache_purging[36442]: Deleting objects expiring before 17:05, 9 July 2020 |
| 42 | Jul 12 08:39:17 mwmaint1002 mediawiki_job_parser_cache_purging[128375]: Deleting objects expiring before 08:39, 12 July 2020 |
| 43 | Jul 14 22:00:43 mwmaint1002 mediawiki_job_parser_cache_purging[100580]: Deleting objects expiring before 22:00, 14 July 2020 |
| 44 | Jul 17 08:42:25 mwmaint1002 mediawiki_job_parser_cache_purging[24302]: Deleting objects expiring before 08:42, 17 July 2020 |
| 45 | Jul 20 01:20:05 mwmaint1002 mediawiki_job_parser_cache_purging[64583]: Deleting objects expiring before 01:20, 20 July 2020 |
| 46 | Jul 22 23:32:32 mwmaint1002 mediawiki_job_parser_cache_purging[253940]: Deleting objects expiring before 23:32, 22 July 2020 |
| 47 | Jul 26 00:31:13 mwmaint1002 mediawiki_job_parser_cache_purging[40242]: Deleting objects expiring before 00:31, 26 July 2020 |
| 48 | Jul 29 06:18:16 mwmaint1002 mediawiki_job_parser_cache_purging[191576]: Deleting objects expiring before 06:18, 29 July 2020 |
| 49 | Aug 1 08:44:23 mwmaint1002 mediawiki_job_parser_cache_purging[29297]: Deleting objects expiring before 08:44, 1 August 2020 |
| 50 | Aug 4 10:56:00 mwmaint1002 mediawiki_job_parser_cache_purging[173135]: Deleting objects expiring before 10:56, 4 August 2020 |
| 51 | Aug 7 22:14:41 mwmaint1002 mediawiki_job_parser_cache_purging[39261]: Deleting objects expiring before 22:14, 7 August 2020 |
| 52 | Aug 11 06:58:47 mwmaint1002 mediawiki_job_parser_cache_purging[258229]: Deleting objects expiring before 06:58, 11 August 2020 |
| 53 | Aug 14 07:15:29 mwmaint1002 mediawiki_job_parser_cache_purging[54964]: Deleting objects expiring before 07:15, 14 August 2020 |
| 54 | Aug 17 06:40:56 mwmaint1002 mediawiki_job_parser_cache_purging[100453]: Deleting objects expiring before 06:40, 17 August 2020 |
| 55 | Aug 20 01:53:44 mwmaint1002 mediawiki_job_parser_cache_purging[231161]: Deleting objects expiring before 01:53, 20 August 2020 |
| 56 | Aug 22 22:47:23 mwmaint1002 mediawiki_job_parser_cache_purging[185114]: Deleting objects expiring before 22:47, 22 August 2020 |
| 57 | Aug 25 20:14:44 mwmaint1002 mediawiki_job_parser_cache_purging[175794]: Deleting objects expiring before 20:14, 25 August 2020 |
| 58 | Aug 28 21:03:15 mwmaint1002 mediawiki_job_parser_cache_purging[38037]: Deleting objects expiring before 21:03, 28 August 2020 |
| 59 | Sep 1 04:16:18 mwmaint1002 mediawiki_job_parser_cache_purging[254032]: Deleting objects expiring before 04:16, 1 September 2020 |
| 60 | Oct 28 01:00:07 mwmaint1002 mediawiki_job_parser_cache_purging[85535]: Deleting objects expiring before 01:00, 28 October 2020 |
| 61 | Nov 1 13:27:46 mwmaint1002 mediawiki_job_parser_cache_purging[111100]: Deleting objects expiring before 13:27, 1 November 2020 |
| 62 | Nov 5 03:02:09 mwmaint1002 mediawiki_job_parser_cache_purging[125718]: Deleting objects expiring before 03:02, 5 November 2020 |
| 63 | Nov 8 06:52:23 mwmaint1002 mediawiki_job_parser_cache_purging[210463]: Deleting objects expiring before 06:52, 8 November 2020 |
| 64 | Nov 11 04:04:49 mwmaint1002 mediawiki_job_parser_cache_purging[46811]: Deleting objects expiring before 04:04, 11 November 2020 |
| 65 | Nov 13 18:05:08 mwmaint1002 mediawiki_job_parser_cache_purging[23469]: Deleting objects expiring before 18:05, 13 November 2020 |
| 66 | Nov 16 08:24:39 mwmaint1002 mediawiki_job_parser_cache_purging[25291]: Deleting objects expiring before 08:24, 16 November 2020 |
| 67 | Nov 18 11:56:21 mwmaint1002 mediawiki_job_parser_cache_purging[130565]: Deleting objects expiring before 11:56, 18 November 2020 |
| 68 | Nov 21 18:06:30 mwmaint1002 mediawiki_job_parser_cache_purging[145145]: Deleting objects expiring before 18:06, 21 November 2020 |
| 69 | Nov 27 06:01:34 mwmaint1002 mediawiki_job_parser_cache_purging[149815]: Deleting objects expiring before 06:01, 27 November 2020 |
| 70 | Dec 3 06:56:15 mwmaint1002 mediawiki_job_parser_cache_purging[253031]: Deleting objects expiring before 06:56, 3 December 2020 |
| 71 | Dec 9 03:39:20 mwmaint1002 mediawiki_job_parser_cache_purging[144320]: Deleting objects expiring before 03:39, 9 December 2020 |
| 72 | Dec 14 05:59:59 mwmaint1002 mediawiki_job_parser_cache_purging[111951]: Deleting objects expiring before 05:59, 14 December 2020 |
| 73 | Dec 18 08:23:34 mwmaint1002 mediawiki_job_parser_cache_purging[49615]: Deleting objects expiring before 08:23, 18 December 2020 |
| 74 | Dec 21 09:08:16 mwmaint1002 mediawiki_job_parser_cache_purging[149733]: Deleting objects expiring before 09:08, 21 December 2020 |
| 75 | Dec 24 17:45:30 mwmaint1002 mediawiki_job_parser_cache_purging[13185]: Deleting objects expiring before 17:45, 24 December 2020 |
| 76 | Dec 27 23:09:22 mwmaint1002 mediawiki_job_parser_cache_purging[236394]: Deleting objects expiring before 23:09, 27 December 2020 |
| 77 | Dec 31 04:37:15 mwmaint1002 mediawiki_job_parser_cache_purging[209639]: Deleting objects expiring before 04:37, 31 December 2020 |
| 78 | Jan 3 10:12:26 mwmaint1002 mediawiki_job_parser_cache_purging[9945]: Deleting objects expiring before 10:12, 3 January 2021 |
| 79 | Jan 6 22:31:39 mwmaint1002 mediawiki_job_parser_cache_purging[145468]: Deleting objects expiring before 22:31, 6 January 2021 |
| 80 | Jan 10 11:40:57 mwmaint1002 mediawiki_job_parser_cache_purging[37493]: Deleting objects expiring before 11:40, 10 January 2021 |
| 81 | Jan 14 08:21:18 mwmaint1002 mediawiki_job_parser_cache_purging[104818]: Deleting objects expiring before 08:21, 14 January 2021 |
| 82 | Jan 18 10:04:29 mwmaint1002 mediawiki_job_parser_cache_purging[201674]: Deleting objects expiring before 10:04, 18 January 2021 |
| 83 | Jan 23 02:11:11 mwmaint1002 mediawiki_job_parser_cache_purging[131431]: Deleting objects expiring before 02:11, 23 January 2021 |
| 84 | Jan 28 03:31:21 mwmaint1002 mediawiki_job_parser_cache_purging[17858]: Deleting objects expiring before 03:31, 28 January 2021 |
| 85 | Feb 2 01:50:58 mwmaint1002 mediawiki_job_parser_cache_purging[155799]: Deleting objects expiring before 01:50, 2 February 2021 |
| 86 | Feb 7 02:45:33 mwmaint1002 mediawiki_job_parser_cache_purging[99534]: Deleting objects expiring before 02:45, 7 February 2021 |
| 87 | Feb 12 01:00:02 mwmaint1002 mediawiki_job_parser_cache_purging[54460]: Deleting objects expiring before 01:00, 12 February 2021 |
| 88 | Feb 17 08:06:44 mwmaint1002 mediawiki_job_parser_cache_purging[109741]: Deleting objects expiring before 08:06, 17 February 2021 |
| 89 | Feb 22 07:49:48 mwmaint1002 mediawiki_job_parser_cache_purging[213157]: Deleting objects expiring before 07:49, 22 February 2021 |
| 90 | Feb 27 15:09:30 mwmaint1002 mediawiki_job_parser_cache_purging[334]: Deleting objects expiring before 15:09, 27 February 2021 |
| 91 | Mar 5 00:05:42 mwmaint1002 mediawiki_job_parser_cache_purging[7982]: Deleting objects expiring before 00:05, 5 March 2021 |
| 92 | Mar 10 15:46:03 mwmaint1002 mediawiki_job_parser_cache_purging[66538]: Deleting objects expiring before 15:46, 10 March 2021 |
| 93 | Mar 16 19:45:27 mwmaint1002 mediawiki_job_parser_cache_purging[100664]: Deleting objects expiring before 19:45, 16 March 2021 |
| 94 | Mar 23 09:25:13 mwmaint1002 mediawiki_job_parser_cache_purging[120833]: Deleting objects expiring before 09:25, 23 March 2021 |
| 95 | Mar 30 08:56:02 mwmaint1002 mediawiki_job_parser_cache_purging[92844]: Deleting objects expiring before 08:56, 30 March 2021 |
| 96 | Apr 6 02:31:55 mwmaint1002 mediawiki_job_parser_cache_purging[185950]: Deleting objects expiring before 02:31, 6 April 2021 |
| 97 | Apr 13 00:41:29 mwmaint1002 mediawiki_job_parser_cache_purging[17162]: Deleting objects expiring before 00:41, 13 April 2021 |
| 98 | Apr 19 18:08:28 mwmaint1002 mediawiki_job_parser_cache_purging[151047]: Deleting objects expiring before 18:08, 19 April 2021 |
| 99 | Apr 26 02:20:46 mwmaint1002 mediawiki_job_parser_cache_purging[90978]: Deleting objects expiring before 02:20, 26 April 2021 |
| 100 | May 2 01:51:04 mwmaint1002 mediawiki_job_parser_cache_purging[216627]: Deleting objects expiring before 01:51, 2 May 2021 |
| 101 | May 7 05:23:37 mwmaint1002 mediawiki_job_parser_cache_purging[56878]: Deleting objects expiring before 05:23, 16 May 2021 |
| 1 | kormat@mwmaint1002:/var/log/mediawiki/mediawiki_job_parser_cache_purging(0:0)$ grep -E 'Deleting|Done' syslog.log |
|---|---|
| 2 | ... |
| 3 | Jun 6 06:04:16 mwmaint1002 mediawiki_job_parser_cache_purging[99066]: Deleting objects expiring before Sun, 06 Jun 2021 06:04:16 GMT |
| 4 | Jun 8 00:23:24 mwmaint1002 mediawiki_job_parser_cache_purging[99066]: Done |
| 5 | Jun 8 00:23:24 mwmaint1002 mediawiki_job_parser_cache_purging[165238]: Deleting objects expiring before Tue, 08 Jun 2021 00:23:24 GMT |
| 6 | Jun 9 04:15:58 mwmaint1002 mediawiki_job_parser_cache_purging[165238]: Done |
| 7 | Jun 9 04:15:59 mwmaint1002 mediawiki_job_parser_cache_purging[77891]: Deleting objects expiring before Wed, 09 Jun 2021 04:15:59 GMT |
| 8 | Jun 9 19:40:29 mwmaint1002 mediawiki_job_parser_cache_purging[77891]: Done |
| 9 | Jun 10 01:00:04 mwmaint1002 mediawiki_job_parser_cache_purging[91500]: Deleting objects expiring before Thu, 10 Jun 2021 01:00:04 GMT |
| 10 | Jun 10 12:59:34 mwmaint1002 mediawiki_job_parser_cache_purging[91500]: Done |
| 11 | Jun 11 01:00:03 mwmaint1002 mediawiki_job_parser_cache_purging[259200]: Deleting objects expiring before Fri, 11 Jun 2021 01:00:03 GMT |
| 12 | Jun 11 14:47:30 mwmaint1002 mediawiki_job_parser_cache_purging[259200]: Done |
| 13 | Jun 12 01:00:03 mwmaint1002 mediawiki_job_parser_cache_purging[220493]: Deleting objects expiring before Sat, 12 Jun 2021 01:00:03 GMT |
| 14 | Jun 12 16:11:22 mwmaint1002 mediawiki_job_parser_cache_purging[220493]: Done |
| 15 | Jun 13 01:00:04 mwmaint1002 mediawiki_job_parser_cache_purging[181658]: Deleting objects expiring before Sun, 13 Jun 2021 01:00:04 GMT |
| 16 | Jun 13 15:54:56 mwmaint1002 mediawiki_job_parser_cache_purging[181658]: Done |
| 17 | Jun 14 01:00:04 mwmaint1002 mediawiki_job_parser_cache_purging[146932]: Deleting objects expiring before Mon, 14 Jun 2021 01:00:04 GMT |
| 18 | Jun 14 16:02:26 mwmaint1002 mediawiki_job_parser_cache_purging[146932]: Done |
| 19 | Jun 15 01:00:04 mwmaint1002 mediawiki_job_parser_cache_purging[106082]: Deleting objects expiring before Tue, 15 Jun 2021 01:00:04 GMT |
| 20 | Jun 15 17:36:49 mwmaint1002 mediawiki_job_parser_cache_purging[106082]: Done |
| 21 | Jun 16 01:00:03 mwmaint1002 mediawiki_job_parser_cache_purging[65769]: Deleting objects expiring before Wed, 16 Jun 2021 01:00:03 GMT |
| 22 | Jun 16 23:03:33 mwmaint1002 mediawiki_job_parser_cache_purging[65769]: Done |
| 23 | Jun 17 01:00:00 mwmaint1002 mediawiki_job_parser_cache_purging[26955]: Deleting objects expiring before Thu, 17 Jun 2021 01:00:00 GMT |
| 24 | Jun 18 13:42:19 mwmaint1002 mediawiki_job_parser_cache_purging[26955]: Done |
| 25 | Jun 18 13:42:20 mwmaint1002 mediawiki_job_parser_cache_purging[250903]: Deleting objects expiring before Fri, 18 Jun 2021 13:42:20 GMT |
| 26 | Jun 21 08:50:35 mwmaint1002 mediawiki_job_parser_cache_purging[250903]: Done |
| 27 | Jun 21 08:50:36 mwmaint1002 mediawiki_job_parser_cache_purging[62918]: Deleting objects expiring before Mon, 21 Jun 2021 08:50:36 GMT |
| 28 | Jun 23 13:46:56 mwmaint1002 mediawiki_job_parser_cache_purging[118261]: Deleting objects expiring before Wed, 23 Jun 2021 13:46:56 GMT |
| 29 | Jun 28 06:59:28 mwmaint1002 mediawiki_job_parser_cache_purging[118261]: Done |