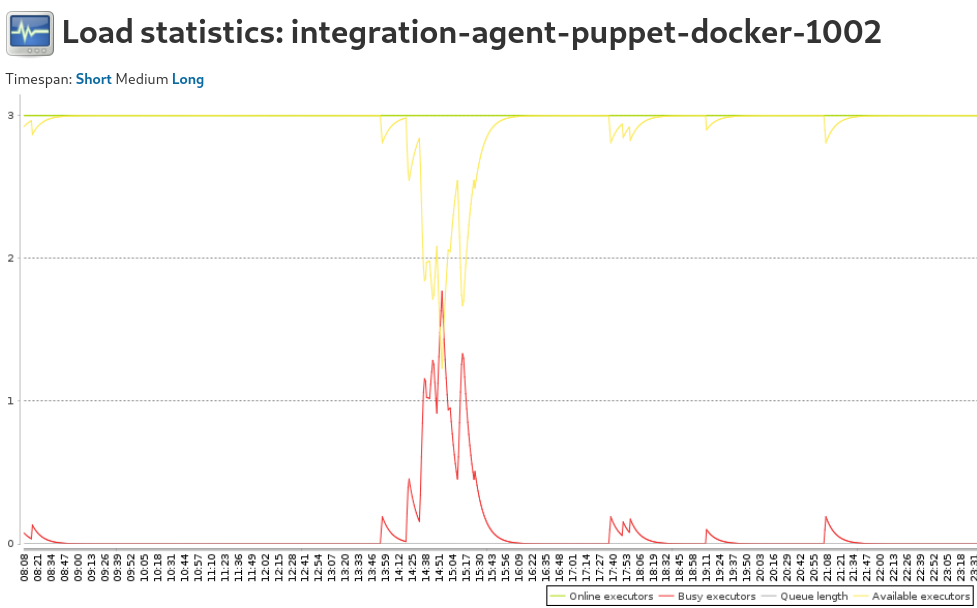
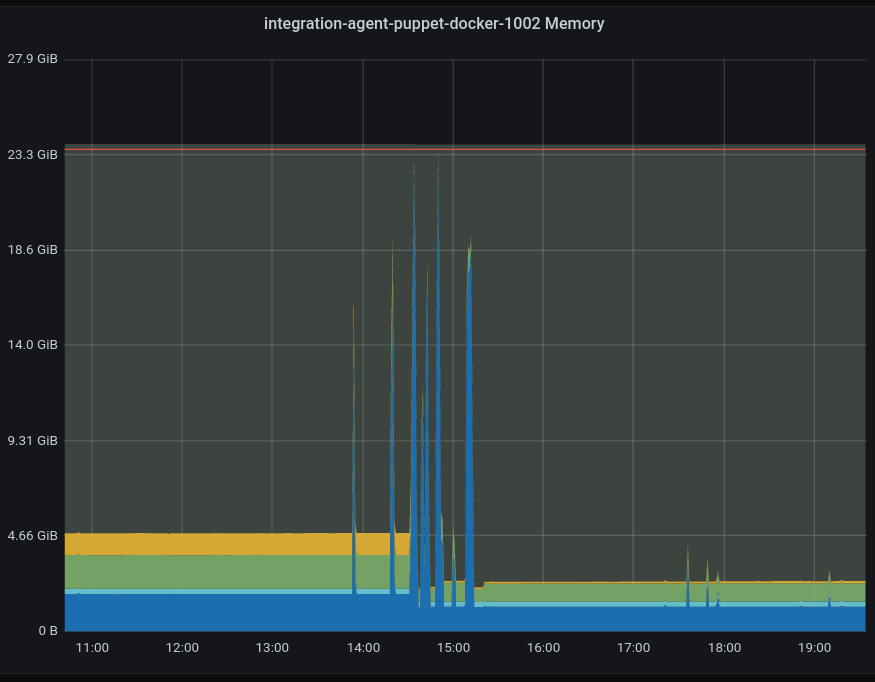
I have noticed to day that the CI jobs have started to fail with the following error
16:50:56 Puppet::PreformattedError: 16:50:56 Evaluation Error: Error while evaluating a Resource Statement, Evaluation Error: Error while evaluating a Function Call, Cannot allocate memory - fork(2) (file: /srv/workspace/puppet/modules/systemd/manifests/timer.pp, line: 38, column: 13) (file: /srv/workspace/puppet/modules/systemd/manifests/timer/job.pp, line: 169) on node 592c993e7595.integration.eqiad1.wikimedia.cloud
The fork in question is a call to /usr/bin/systemd-analyze however it has been in place in the puppet policy for a very log time.
Has anything on the CI images changed which may prevent this fork. or is the CI job now using up all the available memory