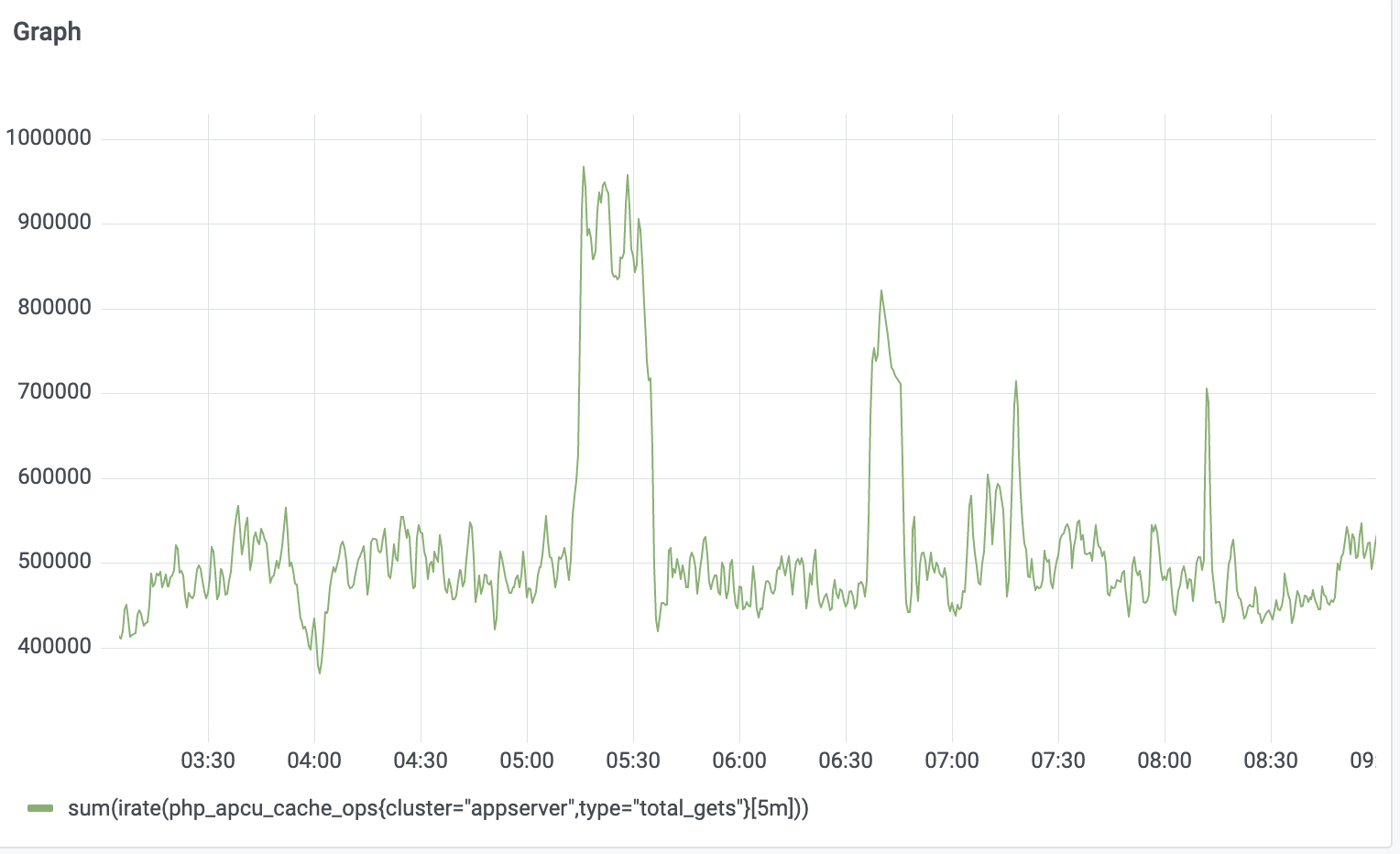
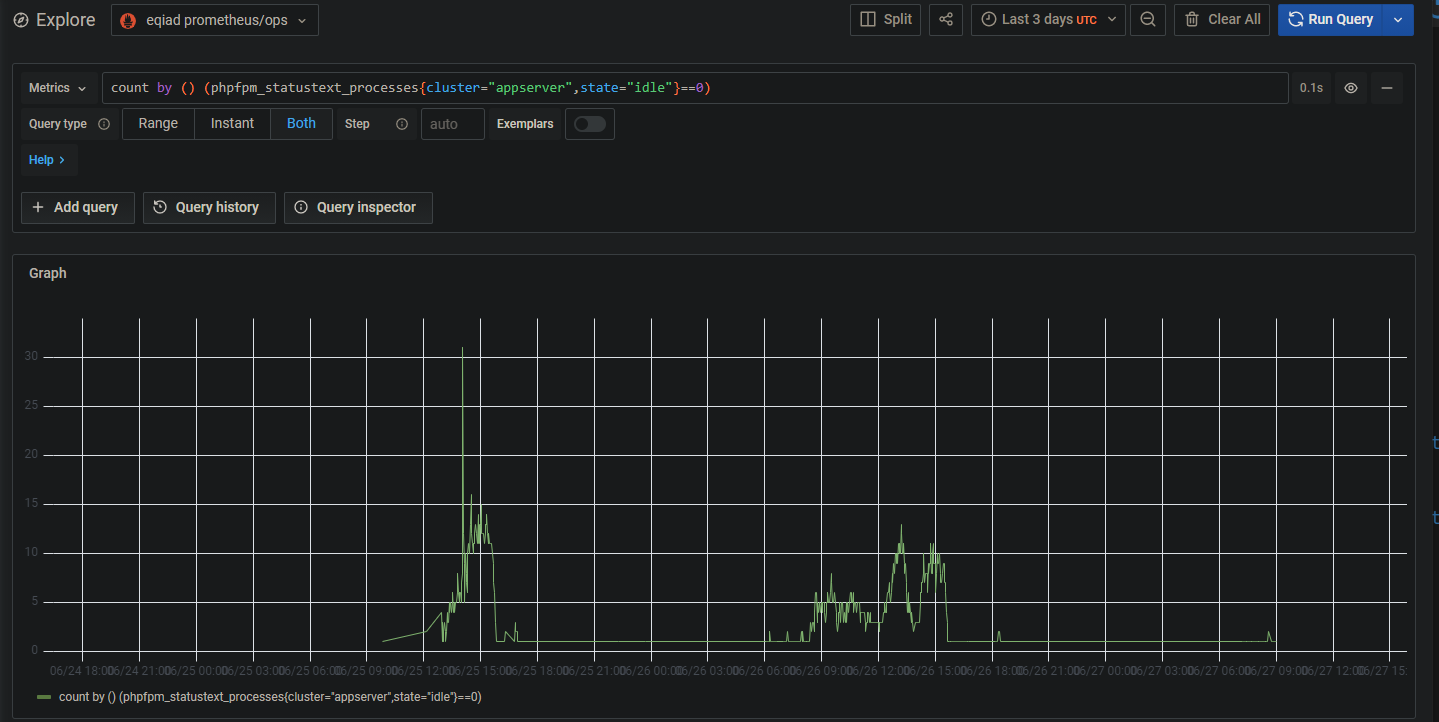
Since approx Friday June 25, appservers seem to be accumulating 'stuck' active workers, which eventually causes a large tail latency impact.
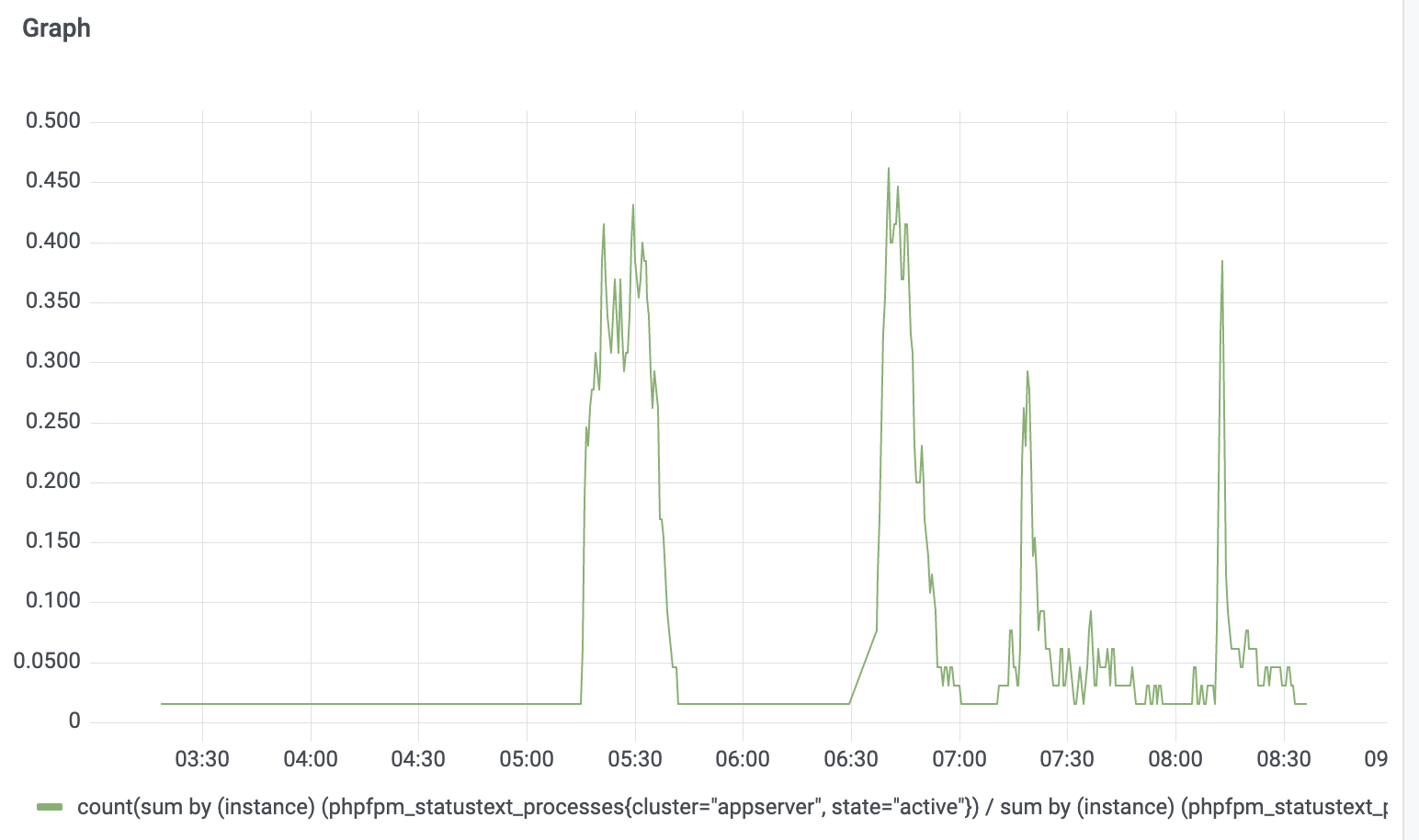
Number of appservers with zero idle php-fpm workers: https://w.wiki/3YvS
Tail latency impact:
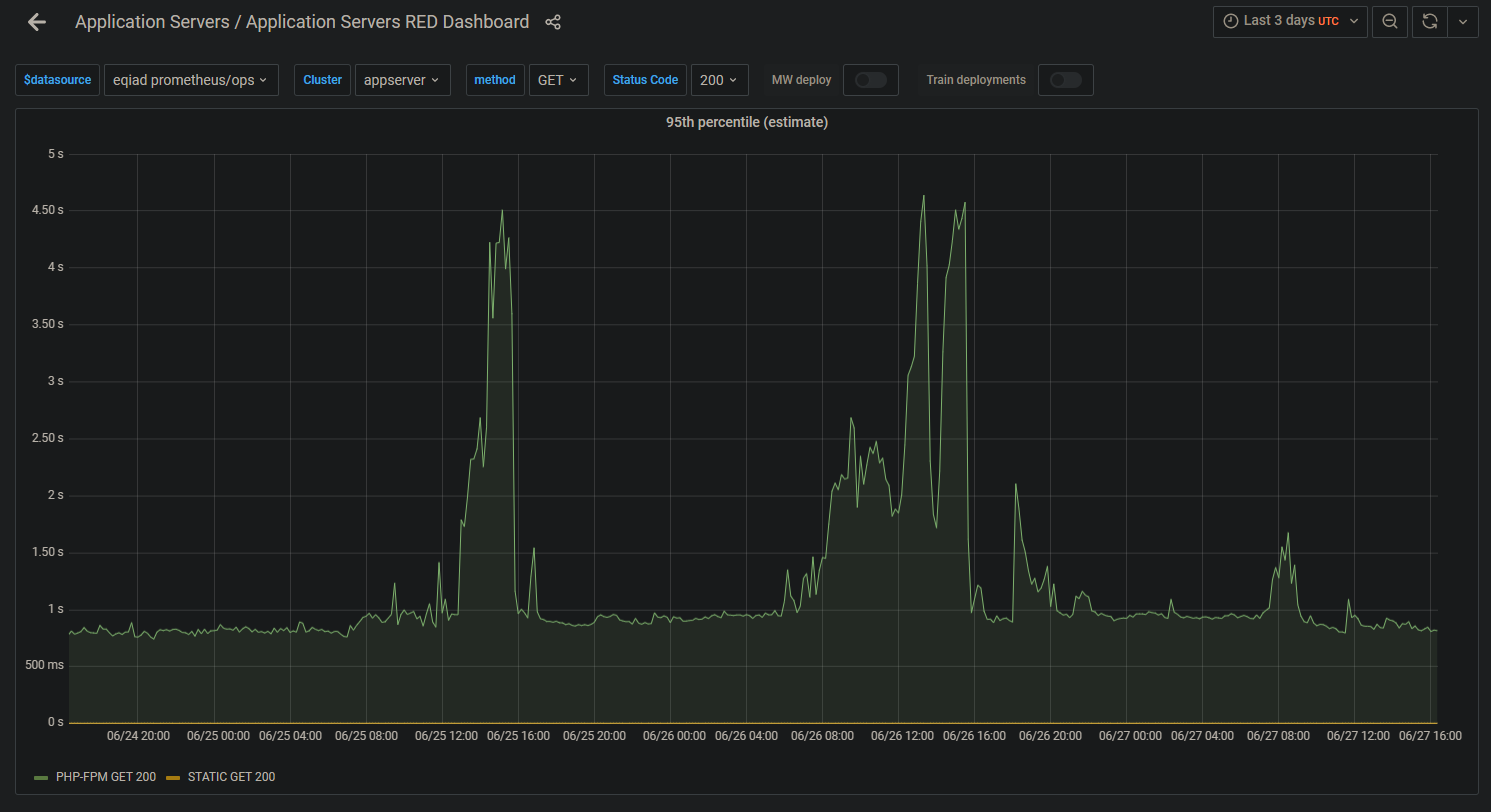
@Dzahn and @elukey and others have been doing various rolling restarts as seen in SAL.
The cause is not clear; perhaps related to a certain kind of request, or perhaps a newly-introduced bug?
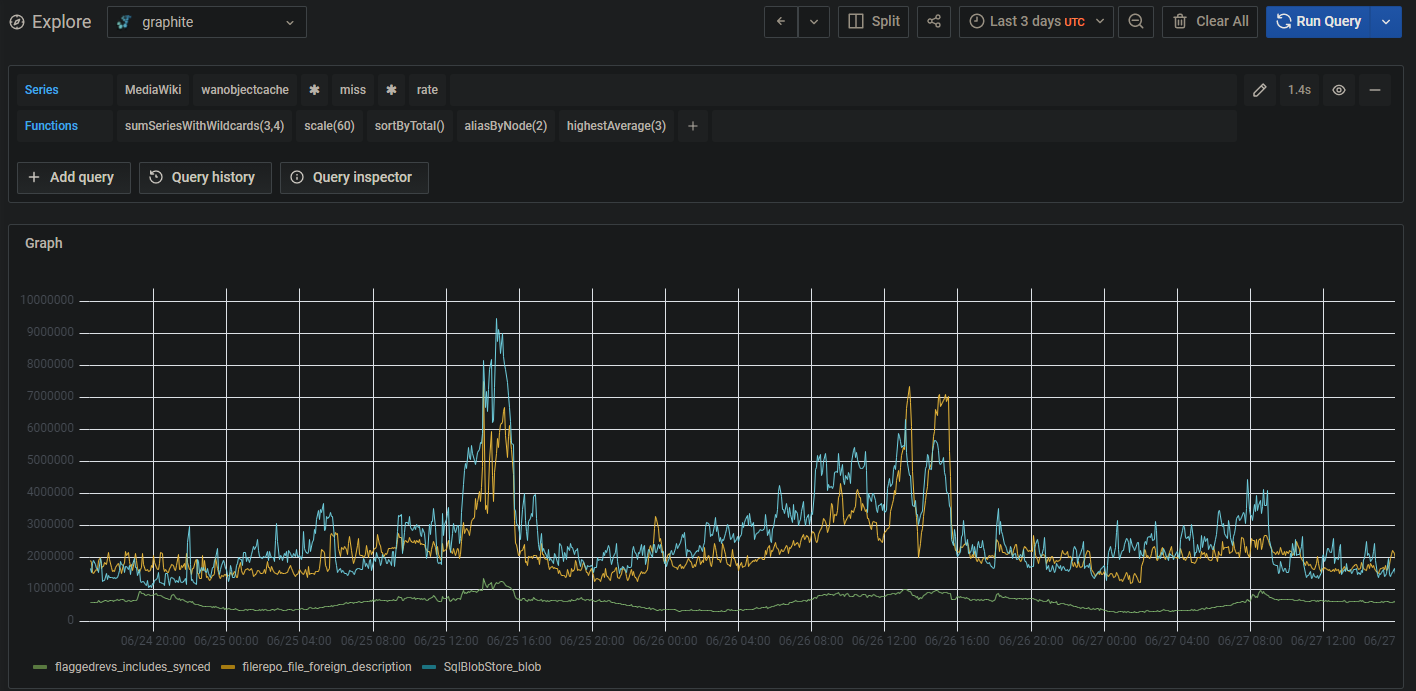
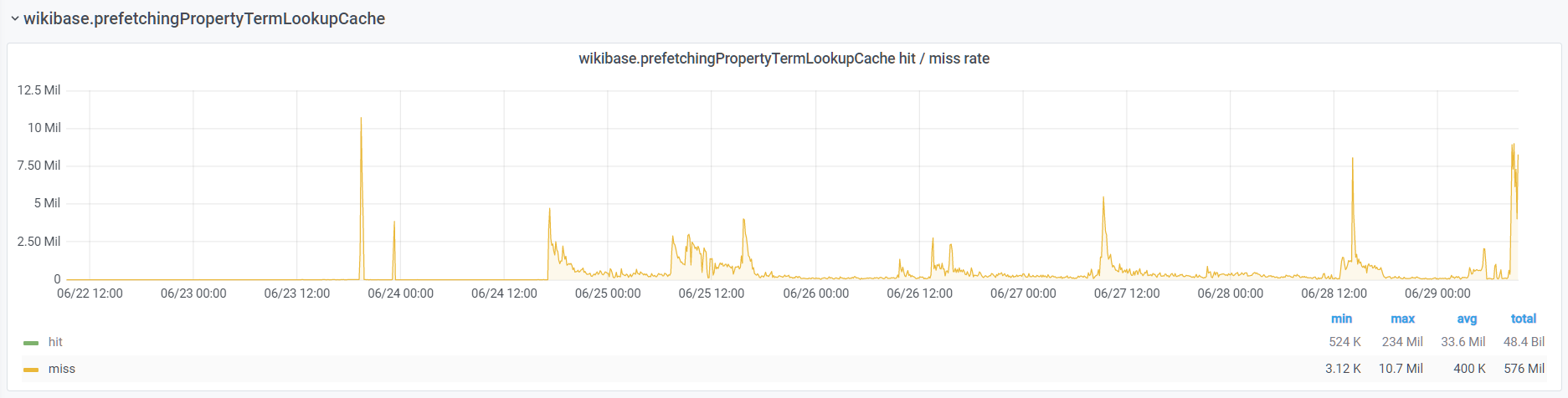
There's also a notable correlation with increased cache miss / regenerations on WANObjectCache types SqlBlobStore_blob and also filerepo_file_foreign_description. Unclear if this is a symptom or a cause.