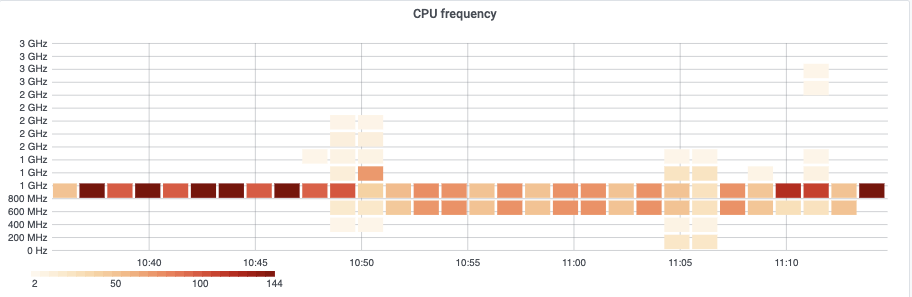
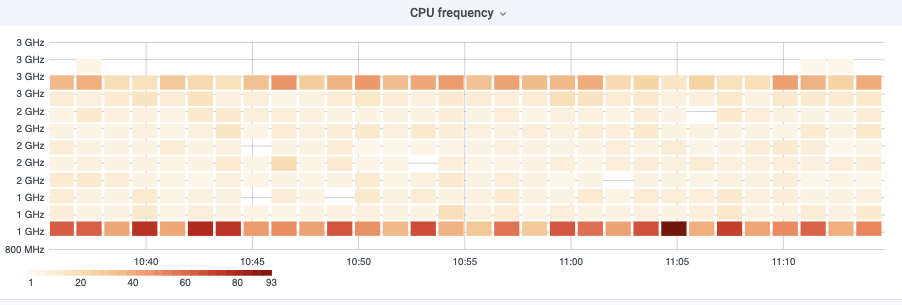
mw2383 was presenting high load and high CPU usage when we switched over from eqiad to codfw (29 Jul 2021). At the time we depooled the server and restarted php-fpm. Today we noticed that it is exhibiting the same behaviour.
Looking at kernel messages, the following messages are logged in higher frequency than other mw* servers:
[Sat Jul 10 12:56:04 2021] traps: php-fpm7.2[15807] general protection ip:7f5cde938013 sp:7ffc2b8afa98 error:0 in libmemcached.so.11.0.0[7f5cde927000+30000] [Sat Jul 10 14:26:42 2021] php-fpm7.2[14795]: segfault at 60000000e ip 00007f5cde93a2f9 sp 00007ffc2b8af880 error 4 in libmemcached.so.11.0.0[7f5cde927000+30000] [Sun Jul 11 20:21:33 2021] Code: 00 31 db 4c 8d ac 24 e0 00 00 00 eb 07 0f 1f 40 00 83 c3 01 4c 89 ff e8 85 16 ff ff 39 d8 76 51 89 de 4c 89 ff e8 47 3f 00 00 <44> 8b 58 0c 49 89 c4 45 85 db 74 db 41 f6 47 01 10 0f 85 c8 02 00 [Mon Jul 12 07:17:38 2021] php-fpm7.2[12304]: segfault at 746e65746e00 ip 0000746e65746e00 sp 00007ffc2b8af288 error 14 [Mon Jul 12 07:17:38 2021] Code: Bad RIP value.
Looking at CPU frequency, it appears that something is triggering throttling and thus not allowing CPU freq to scale up and handle the load
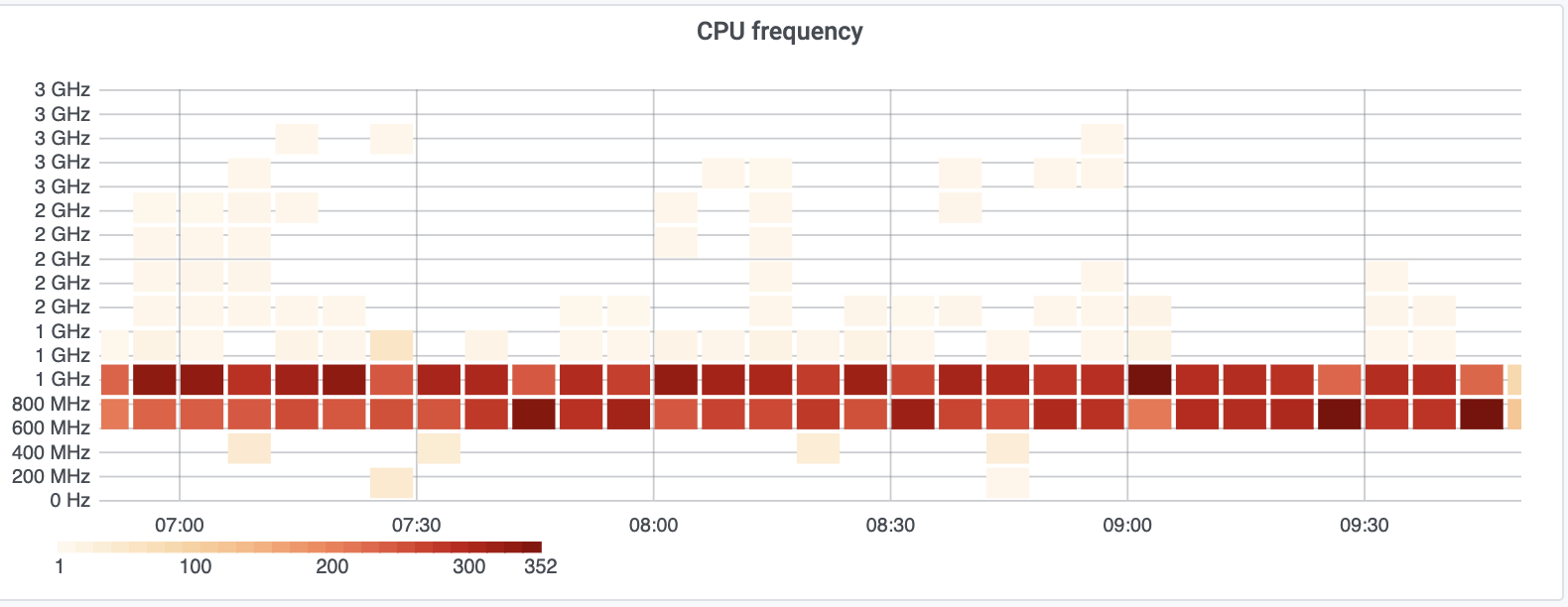
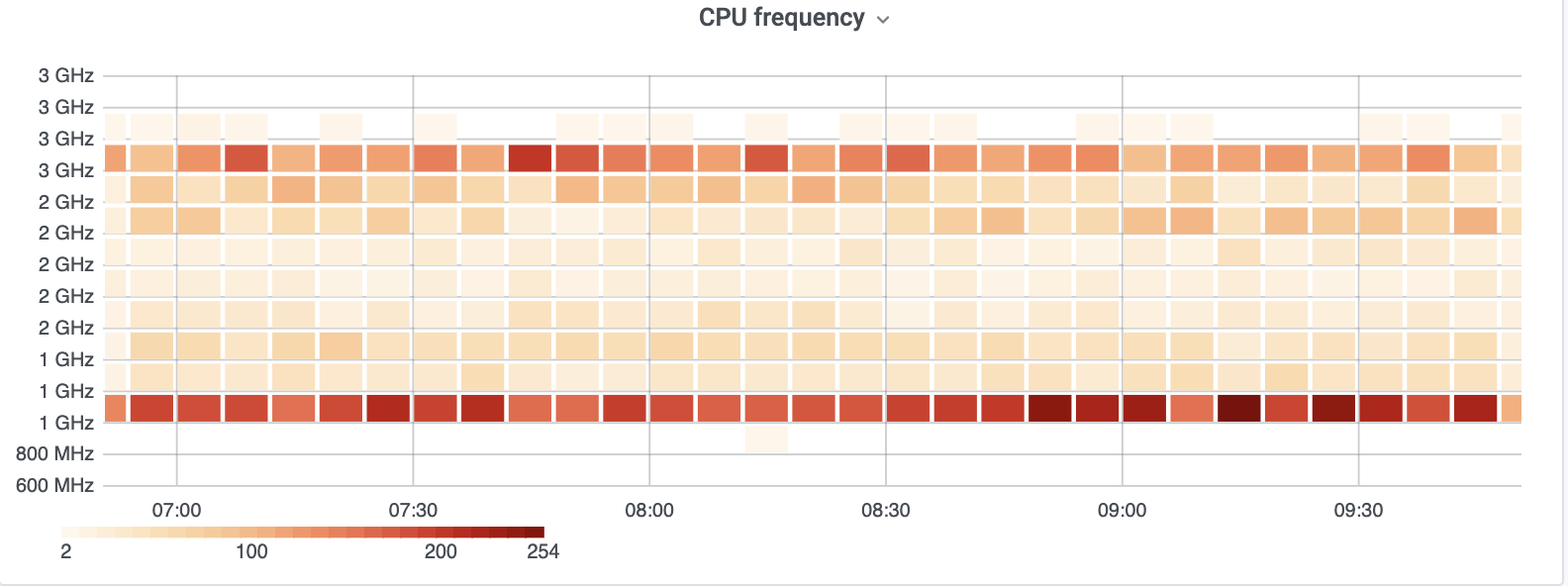
Lastly, intel-microcode is up to date, and nothing interesting stood out when checking the management console log.
DC-Ops, can we check if rhe firmware is up to date? Server is depooled as it was increasing our overall latency.