Error
Large spike in GET requests to McRouter needs investigation/explanation before rolling forward a new train.
Looks like requests doubled when we rolled to group2
| thcipriani | |
| Jun 13 2022, 5:33 PM |
| F35241960: MapCacheLRU overflow fixed.png | |
| Jun 15 2022, 2:30 AM |
| F35241686: Screenshot 2022-06-15 at 01.13.37.png | |
| Jun 15 2022, 1:03 AM |
| F35241679: Screenshot 2022-06-15 at 01.00.28.png | |
| Jun 15 2022, 1:03 AM |
| F35236944: Screenshot-2022-06-13-11:37:54.png | |
| Jun 13 2022, 5:40 PM |
Large spike in GET requests to McRouter needs investigation/explanation before rolling forward a new train.
Looks like requests doubled when we rolled to group2
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Resolved | Release | brennen | T308069 1.39.0-wmf.16 deployment blockers | ||
| Resolved | PRODUCTION ERROR | Krinkle | T310532 Investigate McRouter GET request spike from wmf.15 |
Mentioned in SAL (#wikimedia-operations) [2022-06-14T17:12:58Z] <brennen> train 1.39.0-wmf.16 (T308069): train is blocked - will sync to testwikis and hold there for resolution of T310532
In case it's helpful here, here's a list of everything that went live during that spike: https://www.mediawiki.org/wiki/MediaWiki_1.39/wmf.15/Changelog
It would narrow it down to know what these additional requests were for—how can I find that information? Only in Hive? Or can I find it elsewhere? (I realize I don't have access to Hive).
Is this just the UBN-ness of the back-ported fixes to AbuseFilter for T212129: Move MainStash out of Redis to a simpler multi-dc aware solution?
No, because it's still apparent in prod after that was back-ported. Never mind.
Is this using redis and/or sql? Would this account for an increase in mcrouter GET requests? @tstarling ?
Other changes from last week that mention (cache|sqlblob|wanob)
I looked at web traffic on the localhost of an appserver: no increase in traffic before vs after deploy to account for this. So something in the application is doing more GET requests to memcached independent of traffic.
@JMeybohm Is the increase in requests an increase for any particular key? How would I find that information? Is there a dashboard? Can I grep a thing?
Meeting with Krinkle, Aaron, we think it's because a recent change to zh fallbacks caused the MessageCache MapCacheLRU size to be exceeded, causing a reload of the MessageCache keys on every message instead of once per request.
Change 805497 had a related patch set uploaded (by Tim Starling; author: Tim Starling):
[mediawiki/core@master] Increase MessageCache MapCacheLRU size
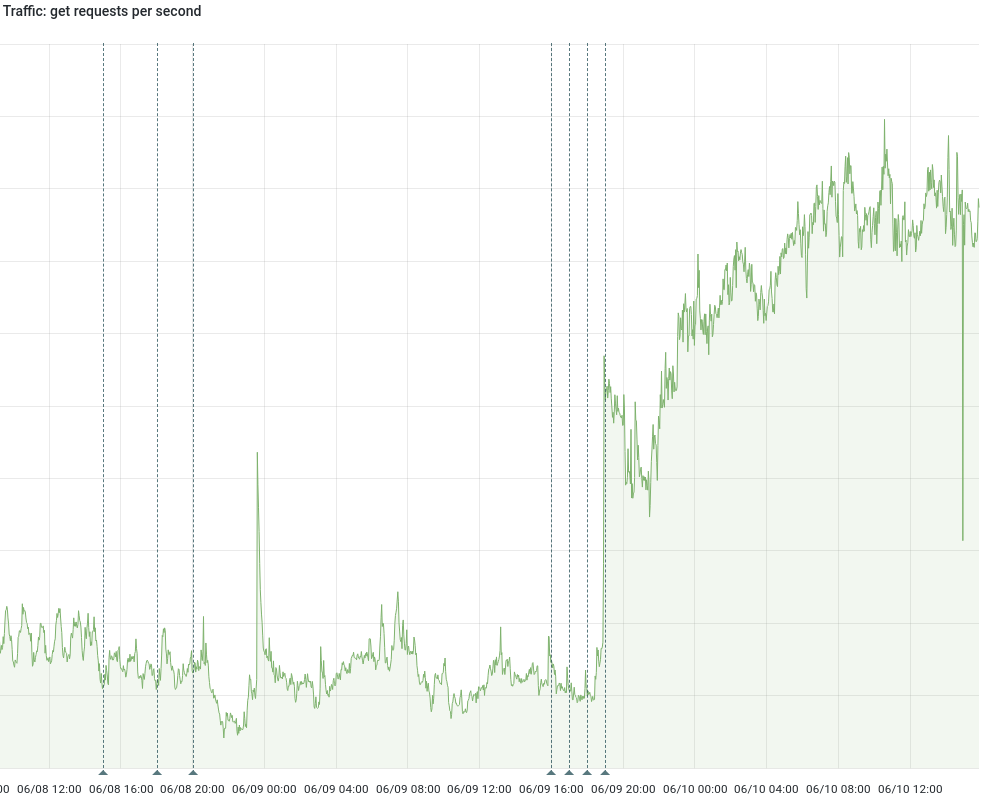
Here goes. Let's start with the actual source of the alert.
This is from the "Application RED" dashboard, and plots memc traffic stats as observed from the appserver-local mcrouter proxy.
Let's start by confirming correlation to the train.
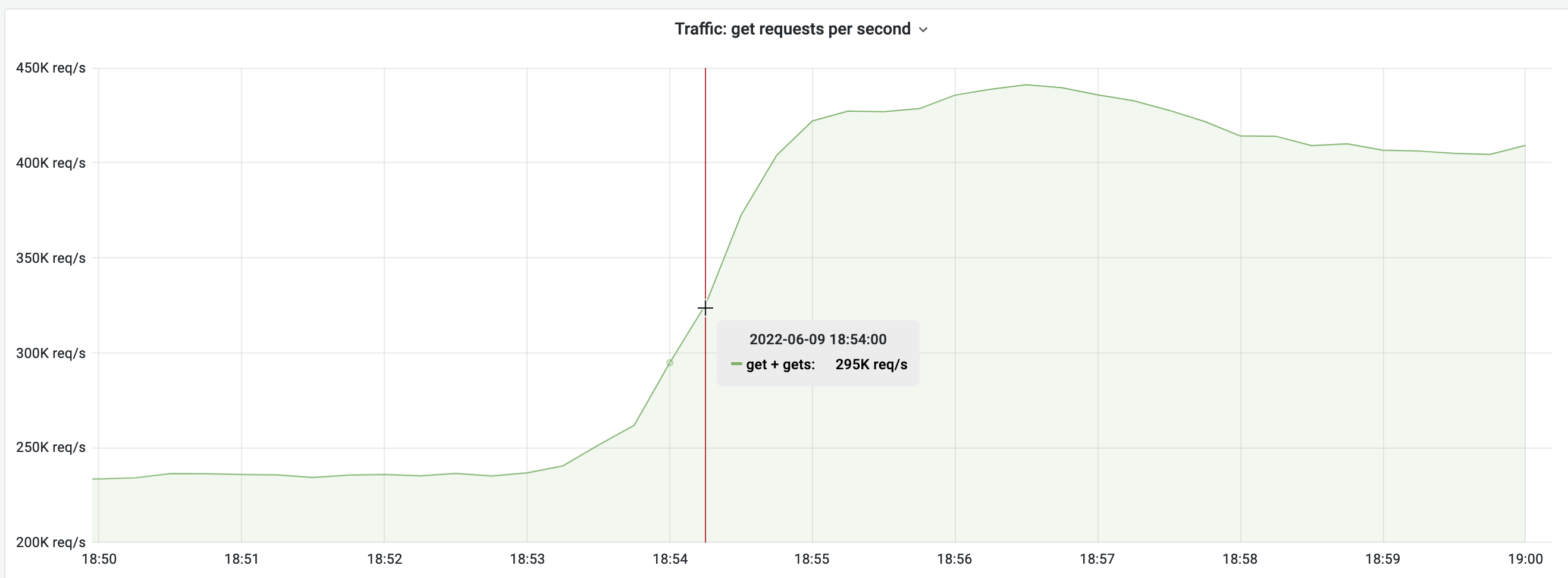
The spike is extremely immediate, taking a single minute to double the request rate, and has sustained throughout the days since. If it weren't that steep a spike, I would have opened the graph editor to see if it got smoothed out by a moving average (e.g. by incorrectly using rate[5m], instead of irate[5m]).
From 18:54-18:56 UTC:
Next up, looking at the breakdown of memcached keys to see if we can pinpoint what MediaWiki component (docs: Memcached at WMF). These stats are provided by the WANObjectCache abstraction layer.
https://grafana.wikimedia.org/d/2Zx07tGZz/wanobjectcache?orgId=1&from=1654560000000&to=1654905599000
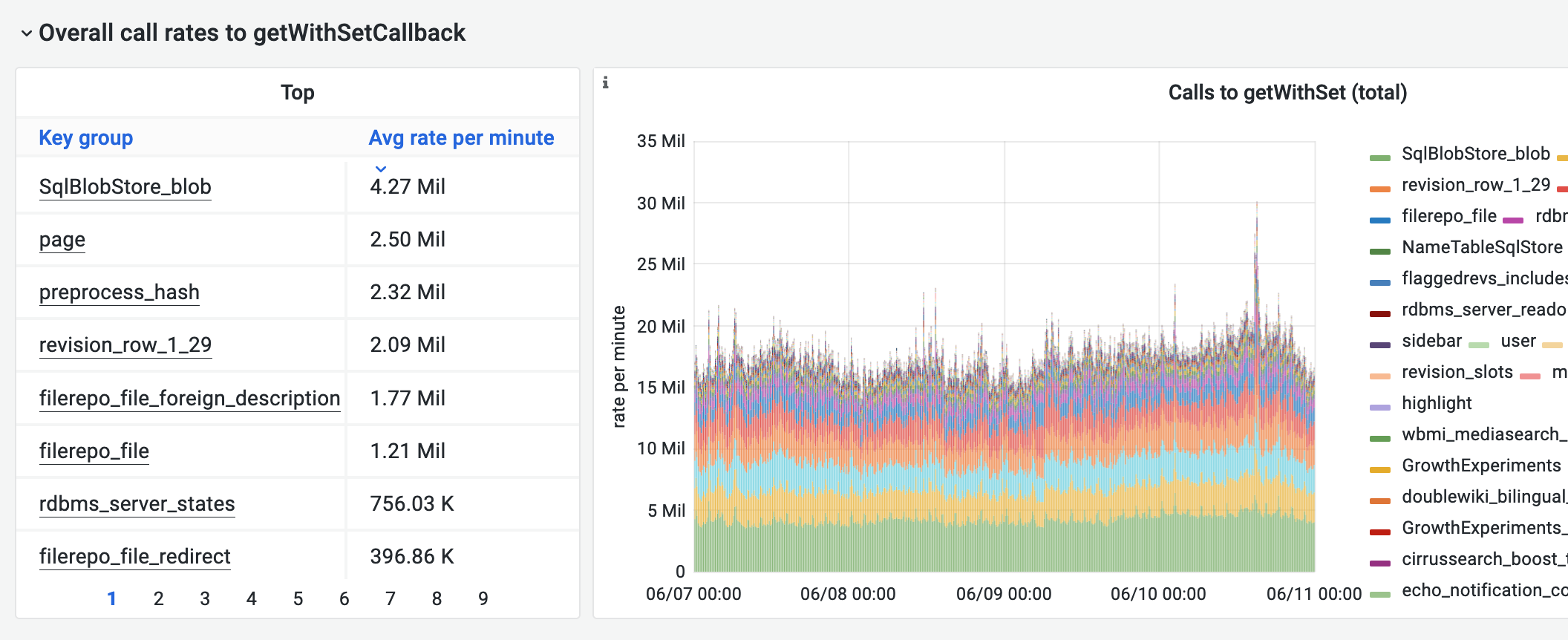
This is suspiciously stable. That's the first sign of something unusual happening here. One thing that comes to mind is that perhaps the cache keys responsible for the doubling are bypassing our WANCache interface? This is very unusual, but possible. (docs: MediaWiki cache interfaces). See also the diagram at wikitech: Memcached for MediaWiki, which shows two or three core features bypassing the WANCache layer and its stats.
As a first pass to look for anything obvious that might have broken our Memcached interactions, I looked at the wmf.15 branch change log (https://www.mediawiki.org/wiki/MediaWiki_1.39/wmf.15). Looking for anything relating to objectcache, cache, purge, memc, wancache, expiry, etc. Nothing stood out however.
To confirm that hypothesis, and to figure out what cache keys are actually responsible, I ran memkeys on one of the servers. I initially checked this on a random memc host, and there the following key stood out as being at least twice as common as the second most key during the 60 second capture.
krinkle@mc1046:~$ sudo memkeys -i ens2f0np0 WANCache:zhwiki:messages:en|#|t … …
One thing of note here, it took me a while to get memkeys to work because last time I used this (~1 year ago?) I ran it as sudo memkeys -i eth0, but that found not such network interface. As per ifconfig, it looks like ens2f0np0 is name of the network interface these days. I'm guessing this is something that changed either in a hardware refresh or as part of a newer Debian version.
I couldn't really tie this to much though, and the wiki-id distribution in the memc traffic didn't look right or representive. I then ran this on an mw appserver instead, to get a more representative sample of the outgoing memc traffic (instead of the incoming traffic on a single memc shard).
krinkle@mw1393:~$ sudo memkeys -i lo -p 11213 memcache key calls WANCache:zhwiki:messages:en:hash:v1|#|v 3525 WANCache:zhwiki:messages:zh-hant:hash:v1|#|v 3486 WANCache:zhwiki:messages:zh-hk:hash:v1|#|v 3469 WANCache:zhwiki:messages:zh-hans:hash:v1|#|v 3466 WANCache:zhwiki:messages:zh-tw:hash:v1|#|v 3463 WANCache:zhwiki:messages:zh-cn:hash:v1|#|v 3385 WANCache:zhwiki:messages:zh:hash:v1|#|v 3347 WANCache:enwiki:pageimages-denylist|#|v 784 … WANCache:enwiki:messages:en:hash:v1|#|v 404 WANCache:global:revision-row-1.29:enwiki:… WANCache:global:rdbms-server-readonly:¬ WANCache:global:resourceloader-titleinfo:… WANCache:enwiki:sidebar:en|#|v … WANCache:zhwikibooks:messages:zh:hash:v1|#|v 75 WANCache:zhwikibooks:messages:en:hash:v1|#|v 75 WANCache:zhwikibooks:messages:zh-tw:hash:v1|#|v 74 WANCache:zhwikibooks:messages:zh-hans:hash:v1|#|v 74 WANCache:zhwikibooks:messages:zh-hant:hash:v1|#|v 74 WANCache:zhwikibooks:messages:zh-cn:hash:v1|#|v 74
@tstarling and @aaron thought that perhaps this is due to the value being too big to be written to Memc. To verify this, we looked at whether the "set" traffic is increased was well. It was not.
We also looked at whether perhaps Mcrouter is depooling an entire memc host as a result of that or other write failures. To verify this, we looked at the Grafana: Memcache dashboard to see if at the backend memcache level, traffic was in fact similarly elevated. In other words, are the mcrouter "gets" actually making it to the memcache backends? They were, there was no dip in traffic on memcache backends not an increase in sets.
This brings us back to the application level.
@tstarling mentions debug logs (docs: WikimediaDebug). We can enable verbose logging for a zhwiki page view, and see what happens. Answering the following questions:
Jun 14, 2022 @ 23:32 DEBUG MessageCache zhwiki MessageCache::load: Loading zh-hk... got from local cache MemcachedPeclBagOStuff debug: getMulti(WANCache:zhwiki:messages:en:hash:v1|#|v, WANCache:zhwiki:messages:en|#|t) MemcachedPeclBagOStuff debug: getMulti(WANCache:zhwiki:messages:zh:hash:v1|#|v, WANCache:zhwiki:messages:zh|#|t) MessageCache::load: Loading en... got from local cache MemcachedPeclBagOStuff debug: getMulti(WANCache:zhwiki:messages:zh-hans:hash:v1|#|v, WANCache:zhwiki:messages:zh-hans|#|t) MessageCache::load: Loading zh... got from local cache MessageCache::load: Loading zh-hans... got from local cache MemcachedPeclBagOStuff debug: getMulti(WANCache:zhwiki:messages:zh-hant:hash:v1|#|v, WANCache:zhwiki:messages:zh-hant|#|t) MessageCache::load: Loading zh-hant... got from local cache MemcachedPeclBagOStuff debug: getMulti(WANCache:zhwiki:messages:zh-cn:hash:v1|#|v, WANCache:zhwiki:messages:zh-cn|#|t) MemcachedPeclBagOStuff debug: getMulti(WANCache:zhwiki:messages:zh-tw:hash:v1|#|v, WANCache:zhwiki:messages:zh-tw|#|t) MessageCache::load: Loading zh-cn... got from local cache MemcachedPeclBagOStuff debug: getMulti(WANCache:zhwiki:messages:zh-hk:hash:v1|#|v, WANCache:zhwiki:messages:zh-hk|#|t) MessageCache::load: Loading zh-tw... got from local cache MessageCache::load: Loading en... got from local cache MessageCache::load: Loading zh-hk... got from local cache MemcachedPeclBagOStuff debug: getMulti(WANCache:zhwiki:messages:en:hash:v1|#|v, WANCache:zhwiki:messages:en|#|t) MemcachedPeclBagOStuff debug: getMulti(WANCache:zhwiki:messages:zh:hash:v1|#|v, WANCache:zhwiki:messages:zh|#|t) …repeat...
This combined with the fact that there are no errors, means the MessageCache class must be doing this multiple times for some reason. Not only are there no error messages from the memcached level, there are in fact "success" message from the MessageCache class. The got from local cache message means it reached the $success = true;'` code path around mediawiki-core: MessageCache.php:L326, and thus marking the language as "loaded". And so there'd be no reason to load it again when the next interface message string is rendered.
At this point, I took another look at the wmf.15 Changelog page. This time looking for message, locali, zh. And... yep:
git #934c9226 - Rearrange zh-related language fallback chain (task T286291) (task T296188) (task T252367) (task T278639) by Winston Sung
https://gerrit.wikimedia.org/r/c/mediawiki/core/+/703560
The change looks suspicious in a number of ways, and is certainly significant. For one, it's the first time (I think?) that were adding fallback from other zh variants to the main zh stub, and also quite a lot of fallbacks that seem potentially redundant. Based on very limited knowledge of how LanguageConverter is used, and the fact that a number of zh- languages have their own wiki, it seems certainly non-obvious that that many fallbacks are desirable from an end-user perspective to be mixed onto a single page view and meshed together. But.. I'm assuming for now that the change was done either through a community request or at least with consensus from editors and translators, and certainly tested to a basic extent locally, and later in Beta or in prod during the past week.
Back to the perf issue for now. The only way that MapCacheLRU $cache->set() can return success and then almost immediately fail again, is... if it got evicted. That's not supposed to happen under normal circumstances. The limit is mainly there to protect against jobs, CLI scripts, and rare batch actions running out of memory from holding on to stuff that was only briefly needed.
class MessageCache { $this->cache = new MapCacheLRU( 5 ); }
And from the above change:
- $fallback = 'zh-hans'; + $fallback = 'zh-hans, zh-hant, zh-cn, zh-tw, zh-hk';
That's 1, 2, 3, 4, 5, plus zh itself makes 6, plus en as source fallback makes 7. 7 is more than 5. Ergo, throughout the page view, we're looping through and.. "mopping the floor while the tap is running", as we say in Dutch.
My gut says it's okay to raise this limit since most notabley this limit is not the LocalisationCache/LanguageFactory limit, which is responsible for a bigger memory payload (the MessageCache is only the light layer over top LC for on-wiki overrides from NS_MEDIAWIKI pages). And there are generally relatively few overrides. And we already exclude "big" messages from the MessageCache blob, to be fetched from their own APCu-cached key without an in-process copy.
For the most part, things were working correctly here.
As @tstarling mentioned during the retro at the end, though, we should definitely have at least a static error of sorts as this is an obvious and determinstic configuration error. It's totally fine to happen at run-time for one reason or another, but we can at least have a structure test in CI to catch when a language is explicitly defined to have more fallbacks than we can hold in-memory and deny that from being merged as-is. Possibly we can also send a warning message to Logstash in production if count(fallbacks) ends up larger than the MessageCache's LRU size constant.
Change 805435 had a related patch set uploaded (by Krinkle; author: Tim Starling):
[mediawiki/core@wmf/1.39.0-wmf.16] MessageCache: Increase the MapCacheLRU size
Change 805436 had a related patch set uploaded (by Krinkle; author: Tim Starling):
[mediawiki/core@wmf/1.39.0-wmf.15] MessageCache: Increase the MapCacheLRU size
Change 805497 merged by jenkins-bot:
[mediawiki/core@master] MessageCache: Increase the MapCacheLRU size
Change 805436 merged by jenkins-bot:
[mediawiki/core@wmf/1.39.0-wmf.15] MessageCache: Increase the MapCacheLRU size
Change 805435 merged by jenkins-bot:
[mediawiki/core@wmf/1.39.0-wmf.16] MessageCache: Increase the MapCacheLRU size
Mentioned in SAL (#wikimedia-operations) [2022-06-15T02:17:24Z] <tstarling@deploy1002> Synchronized php-1.39.0-wmf.15/includes/cache/MessageCache.php: T310532 (duration: 03m 29s)
Change 805501 had a related patch set uploaded (by Tim Starling; author: Tim Starling):
[mediawiki/core@master] Add structure test for Messages*.php files
Thanks much all. @Krinkle, that writeup is a thing of beauty and possibly should be taught as a class on debugging cache issues.
Change 805501 merged by jenkins-bot:
[mediawiki/core@master] Add structure test for Messages*.php files
For the change to fallback chain:
