Patent reveals Google's book-scanning advantage
Google is cagey about exactly how it scans books for its digital library effort, but a patent reveals details--and the hurdles competitors face.


- Shankland covered the tech industry for more than 25 years and was a science writer for five years before that. He has deep expertise in microprocessors, digital photography, computer hardware and software, internet standards, web technology, and more.
Sometimes overlooked in the Sturm und Drang about Google Book Search is any consideration of the mechanics of economically scanning the books in the first place, but a patent awarded to Google gives insight into how the search behemoth accomplishes the task.
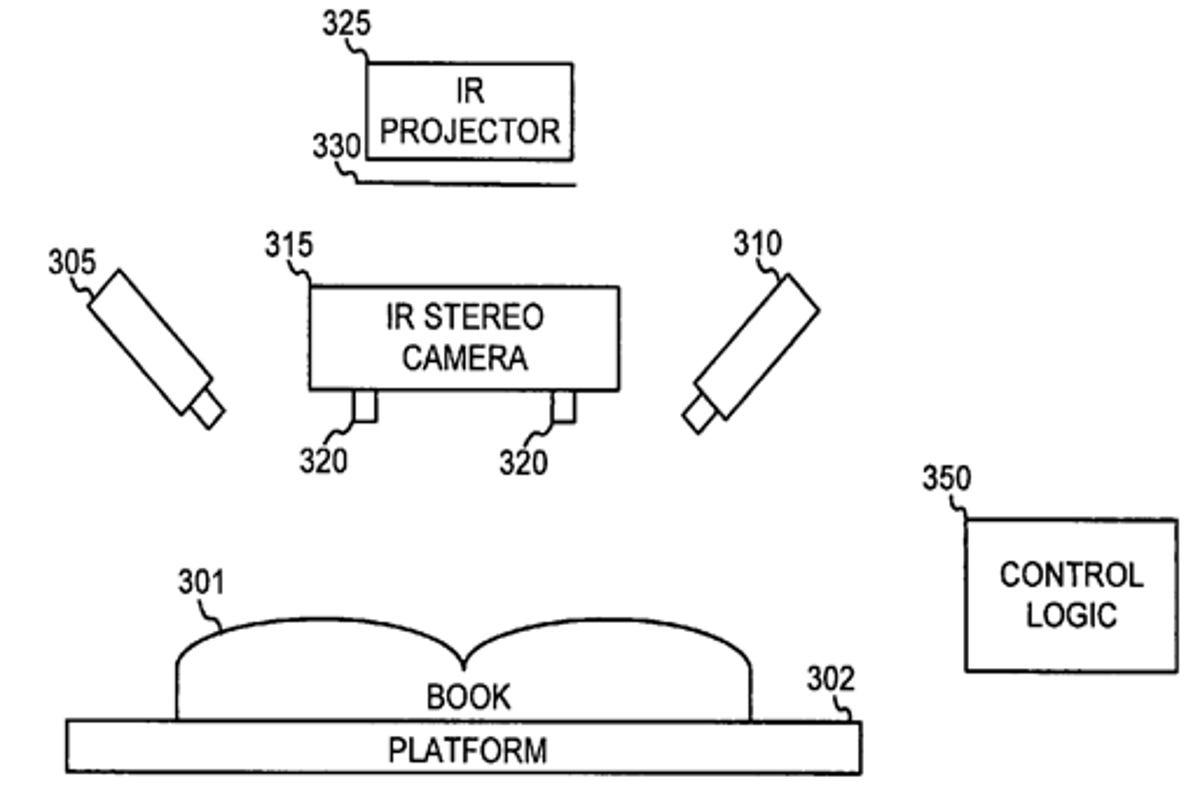
In short, Google has come up with a system that uses two cameras and infrared light to automatically correct for the curvature of pages in a book. By constructing a 3D model of each page and then "de-warping" it afterward, Google can present flat-looking pages online without having to slice books up or mash them onto a flatbed scanner.
The sophistication of the technology illustrates that would-be competitors who want to feature their own digitized libraries won't have a trivial time catching up to Google, which already has scanned more than 7 million books. Any unskilled laborer can plop a book on an ordinary scanner and run some optical character recognition (OCR) operations that convert the imagery into textual data, but doing so rapidly and with high-quality images is another matter.
Here's how the Google system is described in Patent 7,508,978:

First, the book is placed on a flat surface. Above it, an infrared projector displays a special mazelike pattern onto the pages.
Next, two infrared cameras photograph the infrared pattern from different perspectives.
"The images can be stereoscopically combined, using known stereoscopic techniques, to obtain a three-dimensional mapping of the pattern," according to the patent. "The pattern falls on the surface of (the) book, causing the three-dimensional mapping of the pattern to correspond to the three-dimensional surface of the page of the book."
Next, photos of the page taken with conventional cameras can be de-warped, permitting easier OCR and a better image when showing the real book in conjunction with search results based on the text.